MegEngine 虚拟炼丹挑战#
本教程涉及的内容
改进上一个教程中的卷积神经网络模型,理解 MegEngine/Models 库中的 ResNet 官方实现;
学习如何保存和加载模型,以及如何使用预训练模型来进行推理;
整合模型开发常见技巧,总结本系列教程,提供接下来可能的几个学习方向作为参考。
警告
本教程的文风比较独特,假定你正用 MegEngine 参与一场竞赛,希望你能获得有如身临其境的感觉;
我们最终并不会真正地去从零训练一个 ResNet 模型(用时太久),而是掌握其思想。
参见
示范代码大都来自: official/vision/classification/resnet (我们的目的是读懂它)
ImageNet 数据集#
回忆一下在前面几个教程中,我们的讲解思路都是大同小异的,有大量的重复代码模式:
通常我们会介绍一个简单的模型并实现它,然后用于当前教程的数据集;
在下一个教程中,我们仅仅换用了一个更加复杂的数据集,便发现了模型效果不佳;
因此需要设计出更好的模型(借机引入新的相关知识),并进行训练和验证。
在第 2 步中,我们需要修改的主要是数据加载部分,比如调用不同的数据集获取接口; 而在第 3 步中,数据加载则不再被关心,我们专注于模型的设计和超参数的调整。 实际上对于同样类型的任务,相同的模型设计可能可以用于不同的数据集, 甚至只需要在上一个训练好的模型中做一些微调,就能在类似的任务中取得不错的效果。 这不禁让人思考 —— 如何去优化模型开发的流程,以便在面对不同的任务时能够做到更加高效?
这个教程还将帮助你思考一些模块化与工程化问题,接触实际生产中可能采用的工作流程。
了解数据集信息#
ImageNet 数据集与 ILSVRC
ImageNet [1] 里面具有 14,197,122 张图片,21841 个同义词集索引。 该数据集的子集被用于 ImageNet 大规模视觉识别挑战赛 (ILSVRC),作为图像分类和目标检测的基准。 “ILSVRC” 一词有时候也用来特指该比赛使用的数据集(即刚才提到的 ImageNet 的一个子集), 其中最常用的是 2012 年的数据集,记为 ILSVRC2012. 因此有时候提到 ImageNet, 很可能是指 ImageNet 中用于 ILSVRC2012 的这个子集。
MegEngine/Models 中的 ResNet 默认在 ILSVRC2012 数据集上进行训练和评估, ILSVRC2012 中拥有越 120 万张图片作为训练集,5 万张图片作为验证集, 10 万张图片作为测试集(不带标记),总共有 1000 个分类。 ILSVRC2012 有时也叫 ILSVRC 1K, 1K 指的是 1000 个类别。
我们曾在前面的教程中提到过数据集划分的概念,ILSVRC 就是很好的一个例子, 比赛方会提供给你带有标记的训练集、验证集,但最终实际用来排名的是测试集。 参赛人员没有任何途径获取测试集对应的标记,只能将自己的模型在测试集上的预测结果提交给比赛平台, 由后台机器评委结合测试集的标记对最终的结果进行评估(评估指标是公开的)。 在科研文献中,通常比较的是在训练集和验证集上的评估结果。
ResNet 模型获得了2015 年 ILSVRC 的冠军,且其设计思路经过了时间的验证,可谓经典。
警告
使用频率最高的 ILSVRC2012 图像分类和定位数据集目前可以在
Kaggle
获取。但完整的 ImageNet 和其它常用子集并不可以直接地进行获取,
虽然 MegEngine 中提供了相应的 ImageNet 处理接口,
但也仅仅用于对本地数据进行处理,不会进行原始数据集的下载。
ImageNet 的评估指标
Top-1 准确率:预测分类概率中,概率最大的类别与真实的标记一致,即认为正确;
Top-5 准确率:预测分类概率中,概率前五的类别中包含真实标记类别,即认为正确。
这对应了 MegEngine 中的 topk_accuracy 接口,如果用错误率表示,则为 1 - 正确率。
参加 Virtual ILSVRC#
将时间拨回到平行宇宙的 2015 年,你作为 MegEngine 炼丹炉代表队的一员主力, 刚学会了卷积神经网络,原本尝试用 LeNet5 模型参与 ILSVRC 比赛,结果自不用猜… 完全没法看。 铩羽而归绝不是小队的目标,划水观光更不能接受, 现在需要想方设法地进行改进,争取在今年的挑战赛上打出风采。
恺铭、祥禹、韶卿决定加入你的队伍,经验丰富的孙健老师将作为指导,一齐参与 ILSVRC2015 挑战赛!
真实情况是…
何恺明、张祥雨、任少卿和孙剑是论文《Deep Residual Learning for Image Recognition》的作者, 没错这就是 ResNet 模型的对应论文,它获得了CVPR 2016 Best Paper.
注:CVPR 是国际计算机视觉与模式识别会议(Conference on Computer Vision and Pattern Recognition) 的缩写。作为 IEEE 一年一度的学术性会议,会议的主要内容是计算机视觉与模式识别技术。 CVPR 是世界顶级的计算机视觉会议,你可以尝试使用 MegEngine 复现很多经典论文中的实验结果。
后文的情节与实际的历史会有比较大的差异(虚构),会通过此类形式进行说明。

那么问题来了,要如何去做改进呢?解决问题的思路很重要,大家决定从不同的角度来想想办法。
孙老师说:“让我们先来看看过去几年的 ILSVRC 图像分类冠亚军能提供些什么思路吧。”
相关的论文祥禹早已烂熟于心,很快他给出了几篇需要被重点关注的对象:AlexNet, VGGNet, GoogleNet… “这几篇论文的处理思路、模型结构都挺新颖的,值得一看。” 于是大家决定按照时间顺序,从 AlexNet 开始看起。
加大炼丹火力#
传统神经网络中使用 sigmoid 或 tanh 作为激活函数,
AlexNet 中使用了 relu, 这个做法你们已经应用。另外你还注意到,
AlexNet 使用了 2 个 GPU 进行训练! “我们需要更多的 GPU 来节省时间!” 你激动地喊道。
真实情况是…
使用多个 GPU 设备涉及到 分布式训练(Distributed Training) 的概念,相较于单卡训练,这确实能够节省时间。 但在当时的历史背景下,作者 Alex Krizhevsky 使用两个 GPU 的实际原因是当时所用的 GPU 设备(GTX 580)内存不足以存储下 AlexNet 中的所有参数, 因此画出来的模型结构是这样的:
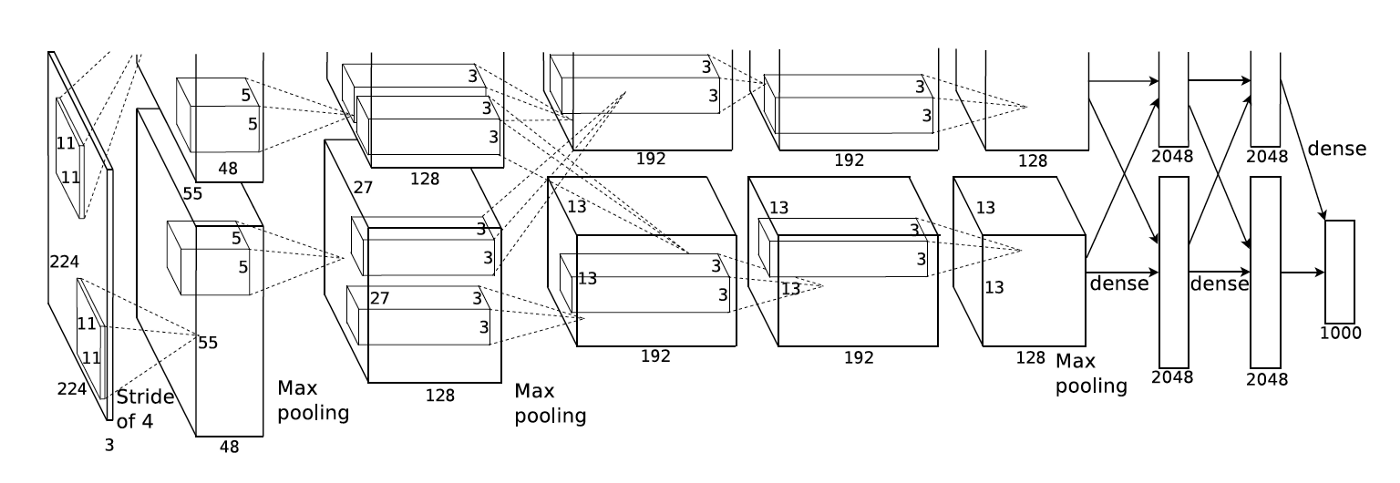
来自论文 ImageNet Classification with Deep Convolutional Neural Networks#
如今的 GPU 设备内存容量足以放下完整的 AlexNet 结构,大部分单卡 GPU 即可进行复现。 但 AlexNet 是第一个利用 GPU 来加速神经网络计算的实验,因此其历史意义非凡, 它标志着一个新的时代已经到来,正所谓 “炼丹用上 GPU, 敢教日月换新天。” 曾经不可行的网络计算,如今已成为家常便饭。赞!感叹!
参见
在 official/vision/classification/resnet/train.py#L112 中支持单个或多个
GPU 进行 ResNet 的训练,其中每台 GPU 设备被看作是一个 worker.
多个 GPU 设备训练时需要关注各种数据同步策略,例如:
# Sync parameters and buffers
if dist.get_world_size() > 1:
dist.bcast_list_(model.parameters())
dist.bcast_list_(model.buffers())
# Autodiff gradient manager
gm = autodiff.GradManager().attach(
model.parameters(),
callbacks=dist.make_allreduce_cb("mean") if dist.get_world_size() > 1 else None,
)
从单卡到多卡,需要用到 launcher 装饰器,更多介绍请参考 分布式训练(Distributed Training) 。
只见孙老师大手一挥:“没问题,给你八张体质贼棒、性能贼强的卡,咱们把火力拉满。”
提升灵材品质#
你正沉迷在多卡妙用的奇思妙想之中,这时候韶卿提醒大家:“AlexNet 还做了数据增强,咱们也可以试试。”
数据增强#
俗话说 “见多识广”,越大的数据集通常可以带来越好的模型性能, 因此数据增强(Data augmentation)是一种十分常见的预处理手段。 但 ImageNet 比赛不允许使用其它的数据集,因此能够采取的做法便是对原有数据集中的图片进行一些随机的处理, 比如随机平移、翻转等等。对于计算机来说,这样的图片可以被看做是不同的, 随机因素使得每次得到的分批数据也都是不同的。举例效果如下:

MegEngine 的 data.transform 模块中对常见的图片数据变换都进行了实现,可以在加载数据时进行:
train_dataloader = data.DataLoader(
train_dataset,
sampler=train_sampler,
transform=T.Compose(
[ # Baseline Augmentation for small models
T.RandomResizedCrop(224),
T.RandomHorizontalFlip(),
T.Normalize(
mean=[103.530, 116.280, 123.675], std=[57.375, 57.120, 58.395]
), # BGR
T.ToMode("CHW"),
]
)
)
“好,这样就可以在加载数据时随机裁剪到 224 的长和宽,并且随机做水平翻转了。”
韶卿快速查了查 MegEngine 的 API 文档,稳稳地将这些操作加上。
同时他也在做 Normalize 归一化的同时,
标记上了图片的通道顺序,“好习惯呀,这波属实是学到了”,你默默在心里竖起了一个大拇指。
真实情况是…
AlexNet 中使用的数据增强操作与这里有些不同,对应 transform.Lighting 接口。
这里演示的数据增强方式是利用 MegEngine 的接口在加载数据后即时地变换处理, 也叫做在线增强。一些情景下我们也可以使用对数据离线增强,即提前地用类似 OpenCV 这样的软件做好增强处理, 这样在加载数据时可以看作是使用了好几个数据集。这种方式需要占用掉更多的空间, 而在线增强每次仅会对当前 Batch 的数据进行随机处理,用完就不再需要了。
将验证集(甚至是测试集,如果你能得到)的数据加入训练集中不能够算作是数据增强, 反而是数据泄露(Data leakage),你的模型可能会在这些数据集上过拟合。
数据清洗#
除了数据增强,你还想到一种可能性:“会不会 ImageNet 本身的数据集质量有问题呢?”
数据的内容和标注质量将对模型的效果造成无法忽视的影响,由于 ImageNet 本质上是一个网络图片数据集, 因此其中会有大量的脏数据 —— 图片内容质量不好,格式不一致(灰度图和彩图混合),标记错误等等情况都存在。 你化身为数据清洗小能手,尝试去人工地清洗这些脏数据,但这样做的效率太低了,于是理智地放弃。
参见
事实上,现在已经有许多不错的数据清洗工具可以帮助我们完成类似的工作, 比如 cleanlab 可以帮助我们找出数据集中错误的标记, 其官方声明在 ImageNet 数据集中找到了接近 100,000 个错误标记!
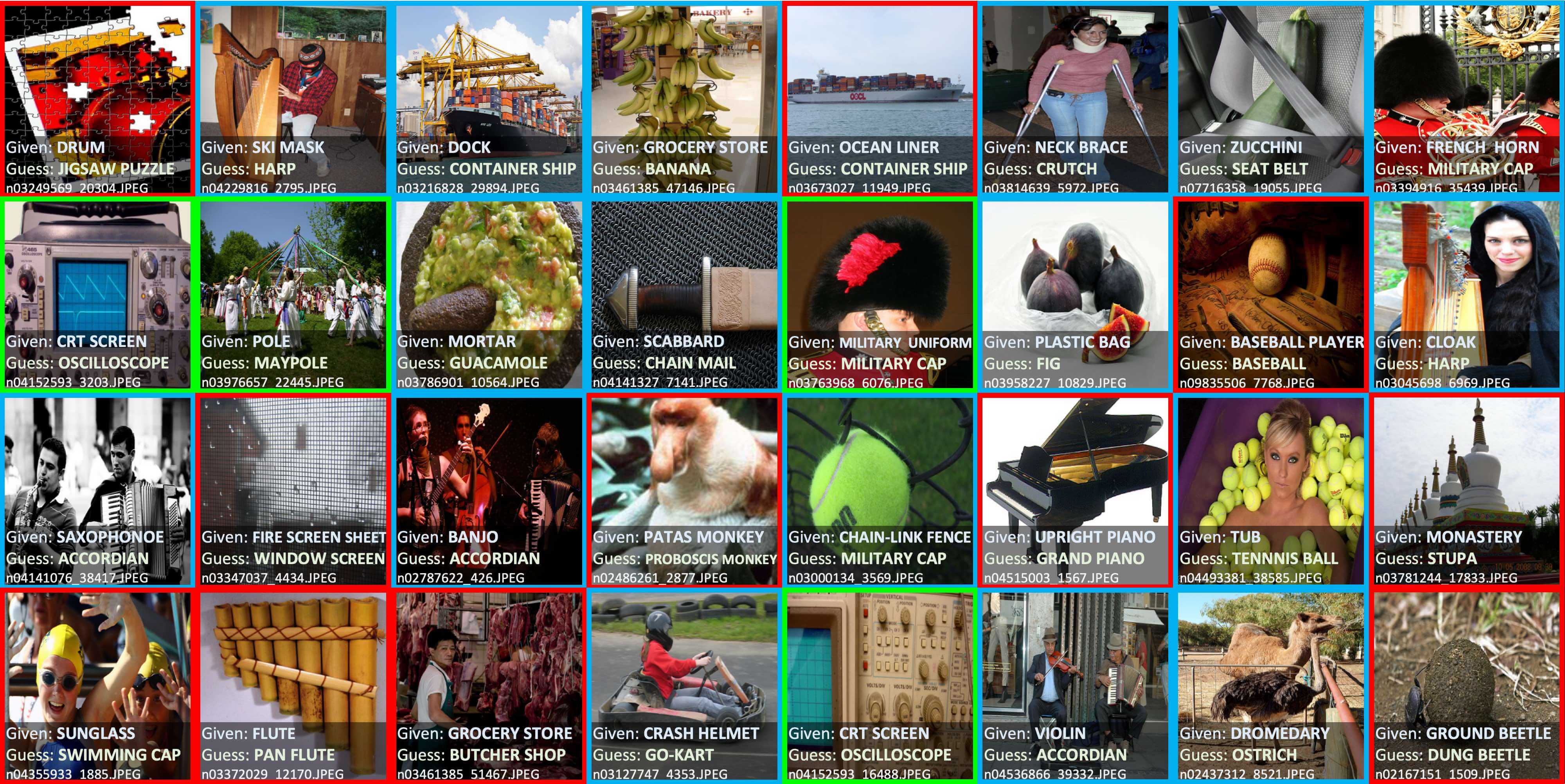
Top label issues in the 2012 ILSVRC ImageNet train set identified using cleanlab. Label Errors are boxed in red. Ontological issues in green. Multi-label images in blue.#
在工业界,你会在一些机器学习团队中看到有专门的数据团队,负责提高数据集质量。合作万岁!
秘制高阶丹方#
当你和韶卿忙活完一阵数据有关的处理后,简单比对了一下实验结果,确实涨了几个点,有效!
但这只能算是和其它人站在了同样的起跑线上,毕竟类似的操作大家都可以用上,也没什么特别的。
接着众人开始继续研究起 AlexNet 和 LeNet5 模型之间的差异。
你发现 AlexNet 中使用到了 Dropout 来防止过拟合,它的思想很简单:
在每次迭代时随机地 “丢掉” 一些神经元,让它失去活性,不参与到计算过程中来。
换而言之,也可以理解成每次训练时只训练一部分神经元,最终等于多个弱分类器装袋在一起发挥功力。
“但是卷积核中的神经元相较于全连接层比较少,用 Dropout 的收益并没有那么明显吧。” 恺铭喃喃了几句。
Batch Normalization#
大家决定继续思考数据特征层面的问题,在输入数据时通常会进行一次 transform.Normalize 归一化,
这样可以让数据的特征分布较为统一,可以加速收敛。但数据之间必然还存在着差异,
而神经网络中隐藏层参数的更新会导致输出数据的分布发生变化,随着层数的增加,这种偏移现象会更严重。
“如果说神经网络的本质就是在对数据的分布进行学习的话,隐藏层的计算使得数据分布变化后,
就不得不学习变化后的分布了,这可能会导致训练不够稳定,难以收敛。”恺铭发出了疑惑。这时祥禹补充道:
“我记得 VGGNet 的模型结构最深做到了 19 层,但再继续加深下去,就很难取得更好的效果了。”
随即他将 VGGNet 论文中的模型结构给展示了出来:
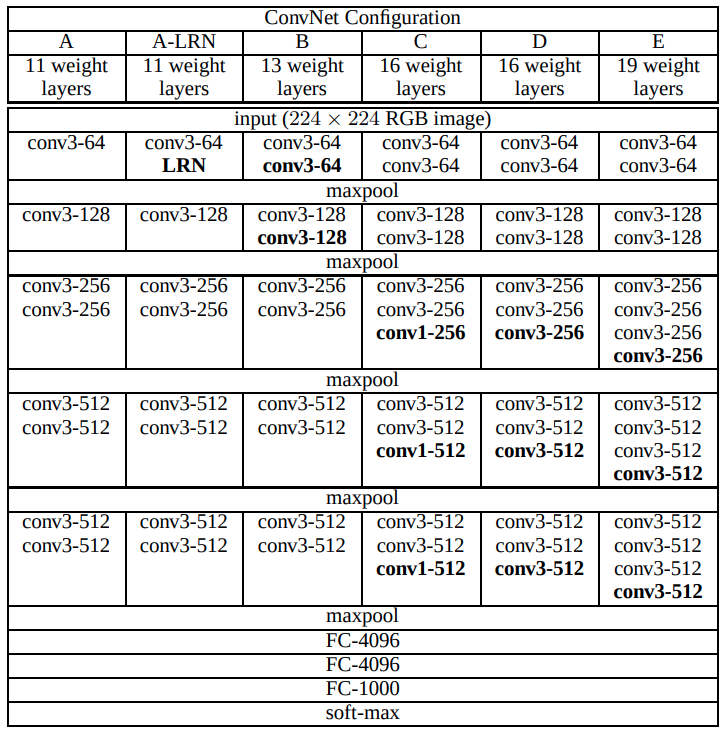
VGGNet 配置,来自论文《Very Deep Convolutional Networks for Large-Scale Image Recognition》#
“除了结构更深了,它和 AlexNet 的区别还在于卷积的 kernel_size 没有像 AlexNet 那么大,统一改成了固定的
\(3 \times 3\) 卷积核,一些地方是 \(1 \times 1\) 的。 ” 你仔细一看,思索起刚才关于数据的讨论。
孙老师此时给出了建议:“既然预处理的时候做归一化有用,你们每层变化完之后也这样处理一下,是不是会有帮助呢?”
祥禹立即开始上手写代码,在 Conv2d 层计算完后,基于当前 Batch 的数据统计出了均值和方差,进行 Normalize 操作。
然后将这个接口添加到了 MegEngine 中,名为 BatchNorm2d.
给 VGGNet 加上 BN 层后,虽然每个 Epoch 多了些计算,但整个训练过程收敛得更快了,最终真的涨点了!
真实情况是…
Batch Normalization 其实来自论文 《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》, 作者是 Sergey Ioffe 和 Christian Szegedy. 只是因为 ResNet 模型中用到了它,因此这里强加了一些设定。 BN 在实践上确实有着能够加快训练稳定性、收敛速度,以及防止过拟合的作用。 最开始的框架并没有现成的接口,因此研究人员需要自己实现 BN 的计算和反传逻辑。 (当时张祥雨是 ResNet 作者中编码功力最强的人,还懂得 CUDA,负责底层框架和编码实现。)
关于 BN 的更多介绍可以参考下面这个视频:
备注
这个视频的制作者是来自旷视研究员的王枫研究员,使用的软件是 Manim. 欢迎读者们制作更多类似的小视频,我很乐意将其作为 MegEngine 文档、教程中的补充知识。
更多关于 Batch Normalization 的解释
曾经一种热门的解释是 Batch Norm 可以解决深度神经网络训练是内部存在的协方差偏移(Internal Covariate Shift)现象, 但后来也有相关论文用实验证明这个结论不成立。因此 BN 更多地变成了一种人们常用的技巧(Trick), 深度学习领域还有很多类似的技巧没能得到严谨的理论支撑,也有不少学者正在研究神经网络的可解释性。 事物的发展总是螺旋上升的,或许没有永久成立的理论(可能在一个更大的框架中被推翻),但却有着当下有用的理论。 实践是检验真理的唯一标准,深度学习领域目前还需要人们多想多实践,等待理论解释的到来。
同样地,在使用了 BatchNorm2d 后,通常可以不再使用 Dropout (这也是实践经验)。
还有的真实情况是…
VGGNet 中将大 Kernel 改成小 Kernel 确实有一定的实践层面的解释,但就像大数据和小数据、大模型和小模型之间的讨论一样, 目前人们还没有一个严格的理论能证明小 Kernel 一定比大 Kernel 有效,换而言之, 从其它的一些层面来看,或许大 Kernel 在特定的情景下将会比小 Kernel 更加适用。
已经发布的论文中的观点如果没有严谨的数学证明,那么很有可能在将来被新的观点取代。 因此在阅读论文时,更多地是需要代入到作者当时的环境,在当时的实验条件和背景下,理解作者解决问题的思路。
参见
在 BaseCls 的 VGG 模型代码中,你可以看到带 BN 层的 VGGNet 与不带 BN 层的 VGGNet 模型。
警告
BN 和 Dropout 存在的一个共同点是:在训练时要用到它们,而实际评估和使用时则不需要。
在 MegEngine 的 Module 中提供了
train 和 eval 两个方法,来切换训练和评估模式。
奇妙的初始化策略#
大家都意识到:神经网络想提升能力就得持续加深,但加深就难收敛,BN 的改进只是一小步。
某天夜半时分,MegEngine 炼丹炉微信群里突然收到了祥禹发来的一条消息:“我有点子了!” 接着过了十几分钟,群里又传来了几张图片,里面是几张潦草的手写草稿。 祥禹提到:“我做了一些独立性的假设,推出了一套参数初始化法则,要不要试试看!” 果不其然,经过验证,使用了祥禹的初始化策略后,整体效果又变好了。 你刚想发个表情包庆祝,结果恺铭、韶卿和孙老师都使用微信拍了拍祥禹 “还没读完的 Paper”, 表示 “我们都没睡呢”。
那就… 趁热打铁吧。大伙又一齐开始研究,设计出了一种新的激活函数 prelu,
对非线性特征进行建模,推导出了符合理论的初始化方法。
你们将新方法应用到了比赛中,结果错误率降低到了 4.94%.
这已经超越了人类识别图像分类的水平(错误率 5.1%),这是 Google 在 2014
年都没能做到的事情!它们的最好成绩只有 6.67%!
for m in self.modules():
if isinstance(m, M.Conv2d):
M.init.msra_normal_(m.weight, mode="fan_out", nonlinearity="relu")
if m.bias is not None:
fan_in, _ = M.init.calculate_fan_in_and_fan_out(m.weight)
bound = 1 / math.sqrt(fan_in)
M.init.uniform_(m.bias, -bound, bound)
elif isinstance(m, M.BatchNorm2d):
M.init.ones_(m.weight)
M.init.zeros_(m.bias)
elif isinstance(m, M.Linear):
M.init.msra_uniform_(m.weight, a=math.sqrt(5))
if m.bias is not None:
fan_in, _ = M.init.calculate_fan_in_and_fan_out(m.weight)
bound = 1 / math.sqrt(fan_in)
M.init.uniform_(m.bias, -bound, bound)
参见
相关实现对应于 module.init 模块中的 msra_normal_,
msra_uniform_ 接口。
真实情况是…
RPeLU 和 MSRA 初始化的工作被发表在论文 《Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification》 中,根据标题就可以发现,这项工作在当时的影响是独特的。
当时 ResNet 的几名作者都在微软亚洲研究院(MSRA)工作,
在内部这个初始化方法被称为 “Xiangyu” 初始化,但后来何恺明去了 FaceBook 工作,
FaceBook 的深度学习框架 PyTorch 中将接口命名为 kaiming_uniform_ 和 kaiming_normal_.
这也是一件奇闻轶事,张祥雨后来来到了旷视研究院,作为旷视科技的深度学习框架,
MegEngine 中也自然可以提供 xiangyu_uniform_ 和 xiangyu_normal_ 接口,
不过为了避免认知负担,外加将人名作为接口不太普遍,最终还是选用了 MSRA 初始化的命名。
(P.S:微信拍一拍功能是 2020 年上线的,故这块的情节显然是刻意虚构的。)
(P.P.S:如果你不知道 FaceBook 是哪家公司的话,可以搜一搜它的新名字—— META.)
残差连接的诞生#
打破纪录固然可喜可贺,但挑战到后面已经慢慢变成了一个工程问题。 祥禹认真地表示:“其实我个人是非常不满意的,因为虽然打败了人类, 但更多是一个噱头,我们也知道这些方法并不很 work,主要是靠调参和堆模型。”
于是祥禹又重新复盘,他发现 2014 年的 ImageNet 冠军谷歌 GoogLeNet 模型复杂度不高,却实现了非常高的准确率, “GoogLeNet 可能是其他几个模型的必经之路。” 他的眼中透流出坚定的目光。 经过几个月的研究,祥禹发现,GoogLeNet 最本质的是它那条 1x1 的 shortcut. “说白了,把它简化到最简单,可以发现 GoogLeNet 只有两条路,一条是 1×1, 另一条路是一个 1x1 和一个 3x3.”
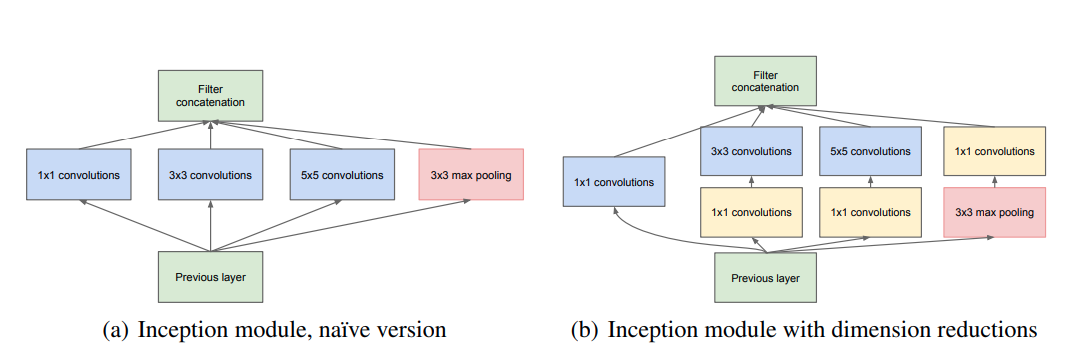
GoogLeNet 中的 Inception 模块,图片来自《Going Deeper with Convolutions》#
“到底是什么在很低的复杂度上支撑起了 GoogLeNet 这么高的性能?”
祥禹猜想,它的性能由它的深度决定,为了让 GoogLeNet 22 层的网络也能够成功地训练起来,它必须得有一条足够短的直路。 基于这个思路,祥禹开始设计一个模型,利用一个构造单元不断的往上分,虽然模型结构的会非常复杂, 但是不管怎么复杂,它永远有一条路,但深度可以非常深。祥禹找到队友们,分享了这个观点: “我认为这种结构就可以保持足够的精度,同时也非常好训练,我把这个网络称为分形网。”
但恺铭觉得:结构还是过于复杂。 “复杂的东西往往得不到本质。”
凯铭建议进一步对这个模型进行化简,用它的一个简化形式。于是祥禹又延伸之前的假设: “最短的路,决定容易优化的程度;最长的路,决定模型的能力,因此能不能把最短路尽可能的短,短到层数为零? 把最深的路,无限的变深?” 基于这个思路,有一条路没有任何参数,可以认为层数是 0 的模型结构诞生了 —— ResNet.
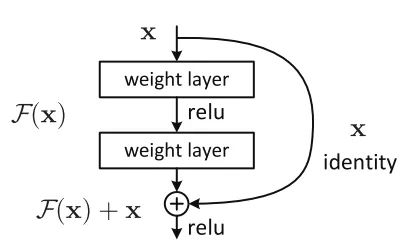
ResNet 中的残差连接,图片来自《Deep Residual Learning for Image Recognition》#
队友们决定让你来实现 ResNet 的模型结构,你把实现的代码放在了 official/vision/classification/resnet/model.py
残差连接的前向计算的逻辑,简洁而优雅,而反向求导过程将由 MegEngine 自动地完成:
def forward(self, x):
identity = x
x = self.conv1(x)
x = self.bn1(x)
x = F.relu(x)
x = self.conv2(x)
x = self.bn2(x)
identity = self.downsample(identity)
x += identity
x = F.relu(x)
return x
借助这个基本结构,你们开始尝试加深网络并训练,看是否能够如期发挥效果。
18 层、34层… 残差连接相较普通结构,在验证集上得到的 Top-1 错误率下降了 3.5%, 且能够收敛,继续加深! 50 层、101 层,效果还在进一步变好!最终你们停在了 152 层结构… 并将测试结果提交给了比赛平台。
ILSVRC’15 分类挑战赛的最终结果出来了,BN-inception(Google 改进后的 GoogLeNet) 在 ImageNet 测试集上的 Top-5 成绩是 4.82, 而 ResNet 的最终成绩是 —— 3.57! 你们士气大涨,使用 ResNet 夺下了 5 项挑战赛的第一。 在孙老师的指导下,你们将 ResNet 的论文投稿到 CVPR 2016, 拿下了最佳论文奖!
“何恺明老师的研究思路对我启发很大,从纷繁的结构中找出最 work 的本质属性, 这种极简化的思想是 ResNet 的核心,并且使得 ResNet 有很强的泛化能力, 任何人都可以在基础上做各种修改,能启发别人的研究。” 祥禹说道。 后来,祥禹和孙老师去了中国一家初创公司,立志在打造东半球最强的计算机视觉研究院。 恺铭去了美国一家科技巨头企业,从事自己的研究工作。韶卿决定投身自动驾驶领域… 你有了这次比赛的经验之后,对炼丹炉 MegEngine 的使用也更加得心应手了, 不论是科研还是工程,你都信心满满,大家都有光明的未来。
真实情况是…
这里所描述的情节参考自《孙剑首个深度学习博士张祥雨:3 年看 1800 篇论文,28 岁掌舵旷视基础模型研究》一文, 部分内容有进行修改,大都为真实历史背景。ResNet 的变体非常多, 其中提出的残差连接的思路,已经在 “深度学习” 魔法世界的大街小巷随处可见。
改进控火技术#
在比赛时,你们还使用到了常用的与模型优化算法有关的技巧。
例如对于 SGD 优化器,你们使用了权重衰减(Weight
decaty)技术,引入了动量(Momentum)(这些参数的意义可查阅文档理解):
# Optimizer
opt = optim.SGD(
model.parameters(),
lr=args.lr * dist.get_world_size(),
momentum=args.momentum,
weight_decay=args.weight_decay,
)
使用到这些技巧时,具体的火候总是不好控制,炼出来的丹药总是奇形怪状的。 但姜还是老的辣,这种情况孙老师早已屡见不鲜,只见他沉声一喝:“调!”, 再用内力一催,丹药在丹炉的火焰中肉眼可见地,缓缓成型。 其余众人喜出望外,孙老师擦去额头汗水,拿出一篇《梯度下降葵花宝典》,说道: “优化算法的实践和理论可多着呢,这算是一篇综述,有空的时候好好研读。”
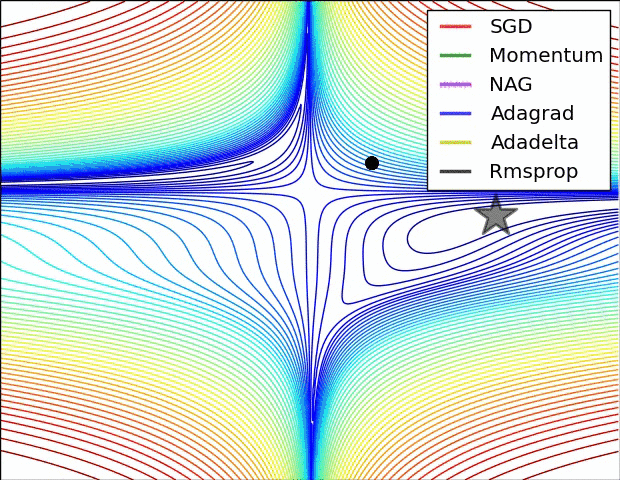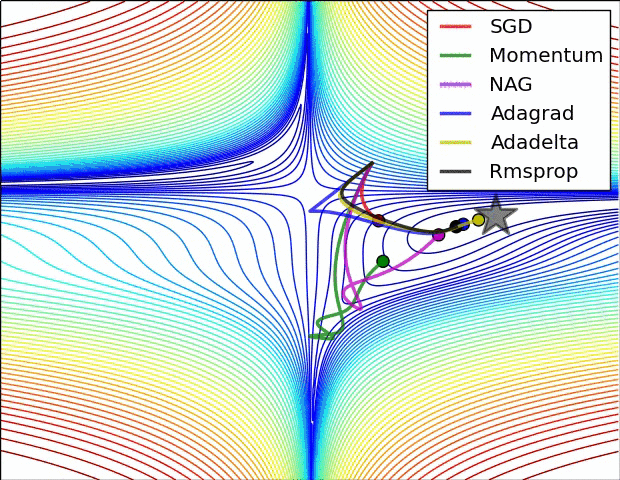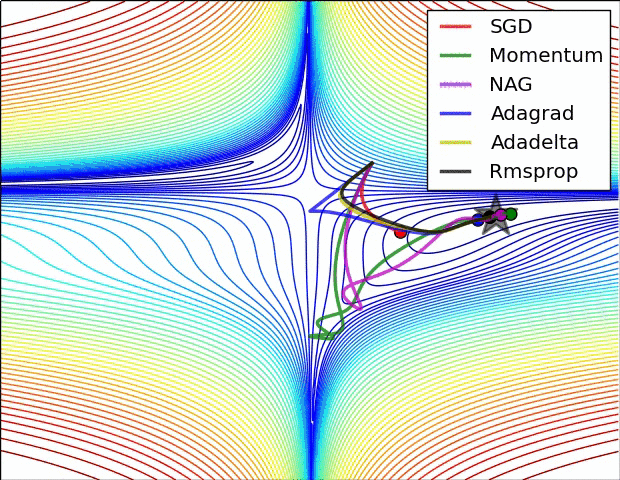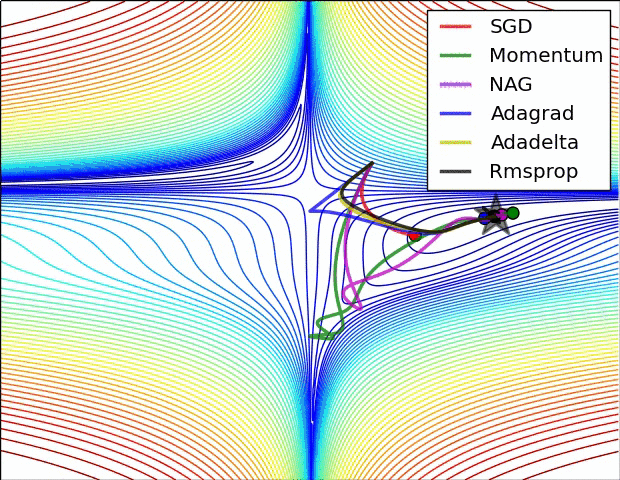
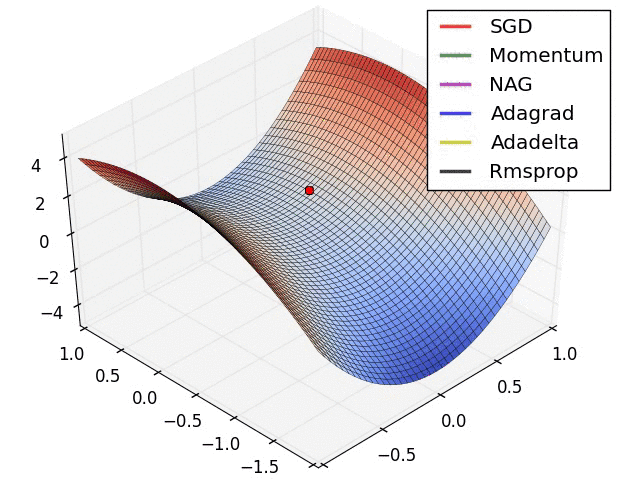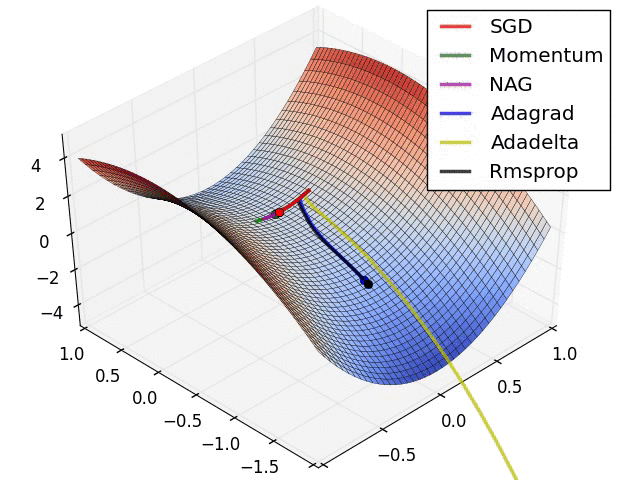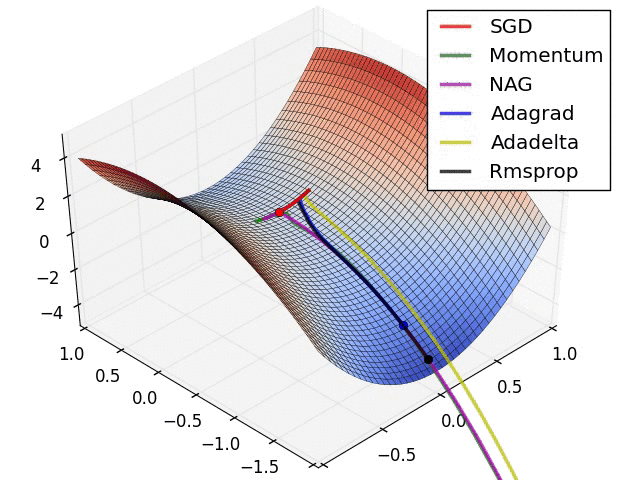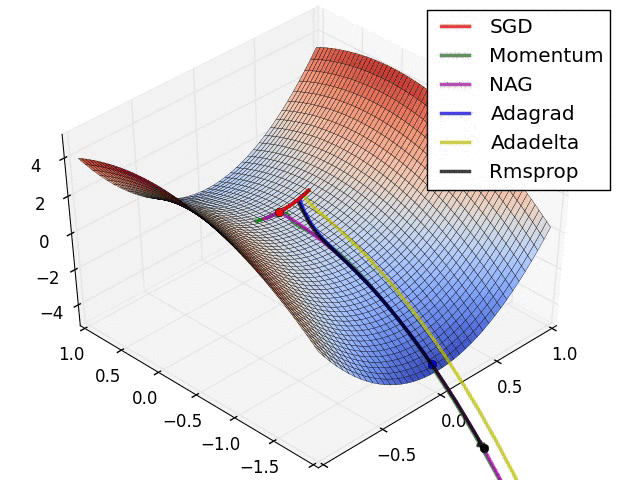
真实情况是…
《An overview of gradient descent optimization algorithms》是一篇挂在 Arxiv 上的文章,
原文形式本是一篇 博客 ,
发布时间是 2016 年,这里只提到了 SGD 的一些改进。
但是其中的一些优化方法如 Momentum 确实在 2013~2015 年就被陆续提出并不断改进。
MegEngine 中的 optimizer 模块实现了常见的优化器,
比如 SGD, Adam 等等,
其功能是可以根据实际需求灵活扩展,用户可以自行设计优化算法。
优化算法孰优孰劣目前还没有定论,学习率调整似乎也存在规律可循,这些都会影响模型的收敛情况。
丹药的产后护理#
在深度学习领域,研究人员复现其他人论文中的实验结果是非常常见的操作。 对于一篇研究论文,如果原作者没有提供实验的源代码,那么其他人只能够尝试去自行复现, 可能会由于一些细节上的差异,导致最终的实验结果差异巨大。 即使提供了模型结构的和训练、测试过程的源码,其他人想要得到一样的模型, 也需要花费掉相当多的时间,且可能因为一些代码中的随机状态得到不同的结果。 因此大部分人在公开自己的研究成果后,为了方便其他人复现实验结果。 会将模型文件和预先训练好的模型参数文件一齐发布,以供其他人进行验证。
参见
在网站 Paper with code 上有非常多前沿实验结果与配套代码,可以尝试参考着用 MegEngine 复现;
关于如何在本地 保存与加载模型(S&L) ,已经在用户指南中有了详细的介绍,这里不再赘述;
为了方便用户快速获取预训练模型,MegEngine 还提供了
hub模块, 能够借助 GitHub/GitLab 分享和下载训练好的模型,方便研究人员使用,参考 使用 Hub 发布和加载预训练模型 。
让我们借助 Hub 从 MegEngine 官方获取预训练好的 ResNet18 模型:
import cv2
import numpy as np
import megengine
import megengine.data.transform as T
import megengine.functional as F
import megengine.hub as hub
image_path = "/path/to/example.jpg" # Select the same image to read
image = cv2.imread(image_path)
transform = T.Compose([
T.Resize(256),
T.CenterCrop(224),
T.Normalize(mean=[103.530, 116.280, 123.675],
std=[57.375, 57.120, 58.395]),
T.ToMode("CHW"),
])
model = hub.load('megengine/models', 'resnet18', pretrained=True)
model.eval()
processed_img = transform.apply(image) # Still NumPy ndarray here
processed_img = F.expand_dims(megengine.Tensor(processed_img), 0) # -> 1CHW
logits = model(processed_img)
probs = F.softmax(logits)
print(probs)
输入数据需要进行相应的预处理(且通道顺序需要一致);
记得将加载好的预训练模型通过
eval接口切换到评估模式;模型接受的输入应当为 Tensor 输入(对于一些模型内部会自动将 ndarray 转 Tensor)。
这样我们就可以加载并使用其他人预训练的 ResNet 模型,进行 1000 个类别上的概率预测了。
总结:欢迎来到深度学习世界#
本套教程已经结束,我们的学习之旅总算告一段落了。 到目前为止,你应当掌握了机器学习、深度学习的基本概念,并且能够使用 MegEngine 编写出简单情景下的神经网络代码,还能够阅读其他人用 MegEngine 编码的作品。 但熟悉这些概念可能依旧需要一些时间,不过… 欢迎来到深度学习世界!
这是接下来为你提供的一些探索方向(取决于你是研究倾向还是工程倾向,亦或者全面发展):
选定分支领域进行研究,使用 MegEngine 复现经典实验
这套教程所有的代码都是围绕着计算机视觉领域的图片分类任务进行的,你可以尝试自己复现 ResNet. 现在是时候去接触更多类型的计算机视觉任务了,比如目标检测、实例风格、超分辨率等等; 你也也可以尝试用深度学习解决的其他传统领域的问题,比如自然语言处理、推荐系统等等。 除了复现其他人的代码以外,你也可以尝试参加一些竞赛,做得多了就会有一些自己的灵感。
为了尝试一些前沿思路,你可能会主动地对 MegEngine 的已有功能进行拓展; 为了节省模型训练的时间,你可能会对 MegEngine 的分布式训练有更多的了解; 在计算资源有限的情况下,为了节省显存,你可能会了解到 MegEngine 的重计算技术… 工欲善其事,必先利其器,不妨了解一下它们的作用。
了解工程实践中的 MLOps
我们目前学习到的所有内容,仅仅只能算作是 MegEngine 模型开发的基础。 想要可靠有效地在生产环境中部署和维护机器学习模型,需要了解整个 MLOps 流程。 以上述 ResNet 预训练模型的推理过程为例子,我们使用了训练所用的 Python (+GPU) 环境, 但我们的目的是希望模型能够部署到其它的平台与设备,在有限条件下进行极致高效推理。 参考 模型部署总览与流程建议 获取更多的细节。
为了服务于业务情景需求,我们会接触到 MegEngine 的更多推理有关的功能。
从零基础状态到 MegEngine 萌新,这是一段难忘的旅途,我们学会了如何将基本的事情做对,并且主动地去思考。 接下来需要漫长的时间,不断尝试将事情做好,让自己成为有经验的 MegEnginer.
拓展材料#
模块化你的项目
在教程中,出于方便展示的目的,我们的代码基本上是以单文件的形式进行组织。 但在实际的编程实践中,为了提高效率,我们应该学会以模块化的形式来组织我们的项目代码。 MegEngine/Models 中的代码是一个很好的例子, BaseCls 也是很优秀的参考。 也希望你能够为社区贡献出更多优秀的 MegEngine 项目~
尝试将教程中的代码进行 data, model, train, test 形式的模块化分拆。
重视 Benchmark 产生的影响
ImageNet 作为计算机视觉领域的经典基准测试数据集,对推动领域发展有着深远意义。 但是研究发展到最后,很容易演变成通过不断实验与调参,达到在验证集上比较高的点。 从某种意义上来说,这也是一种过拟合现象,只不过对象变成了验证集数据。
另外也有实践表明,不少在 ImageNet 上表现良好的模型,用于实际生产任务却不如预期。 这与数据集分布之间的差异有很大关系,比如用油画训练出来的模型可能在素描数据上表现不佳。 因此对于一个特定的深度学习工业情景,需要搞清楚在实际的生产环境中,输入的数据通常是什么样的。 这样在标采用于训练和验证数据时,能尽可能地使得数据的分布相似,建立准确的 Benchmark. 很多时候并不是模型结构本身出现了问题,而有可能是 Benchmark 设置得不够科学。