Module 基类概念与接口介绍¶
注解
神经网络模型的本质可以回归到一系列关于 Tensor 的计算上来,但仅提供 Functional 还不够方便。 Module (模块)可以看作是对 Functional 中算子组合、封装后的一层抽象。 除了负责定义基本的计算流程,还支持嵌套,提供了对内部 Tensor 的管理、记录整体状态信息、前后钩子处理等功能接口。
以下是当前小节的主要介绍内容:
根据模块中的 Tensor 是否是经过反向传播算法更新的,我们区分有 Parameter 与 Buffer 成员;
我们设计的神经网络模块之间可以互相嵌套,参考 Module 嵌套关系与接口;
一些模块在训练和测试时的
forward逻辑不一致,因此需要 转换训练与测试状态 ;借助 Module 状态字典, 我们可以轻松地保存和加载我们的模型状态信息;
模块内部还提供了一些 Module 钩子, 以便灵活地拓展。
Parameter 与 Buffer 成员¶
每个 Module 内维护着一系列重要的成员变量,为了对不同用途的 Tensor 进行区别,有以下概念定义:
在模型训练过程中根据 BP 算法更新的 Tensor (比如
weight和bias) 称为Parameter, 即模型的参数;不需要通过反向传播算法进行更新的 Tensor (比如 BN 中用到的
mean和var统计量)被称为Buffer;可以认为在一个
Module中:Module.tensors = Module.parameters + Module.buffers.
我们从最简单的情况开始,以下面的 SimpleModel 为例(里面没有使用任何内置模块):
import megengine.module as M
from megengine import Parameter
class SimpleModel(M.Module):
def __init__(self):
super().__init__()
self.weight = Parameter([1, 2, 3, 4])
self.bias = Parameter([0, 0, 1, 1])
def forward(self, x):
return x * self.weight + self.bias
model = SimpleModel()
在 __init__ 方法中定义的每个 Parameter 和 Buffer 都由所在的 Module 进行管理。
以 Parameter 为例,我们可以使用 .parameters() 和 .named_parameters() 获取对应的生成器:
>>> type(model.parameters())
generator
>>> type(model.named_parameters())
generator
>>> for p in model.parameters():
... print(p)
Parameter([0 0 1 1], dtype=int32, device=xpux:0)
Parameter([1 2 3 4], dtype=int32, device=xpux:0)
>>> for p in model.named_parameters():
... print(p)
('bias', Parameter([0 0 1 1], dtype=int32, device=xpux:0))
('weight', Parameter([1 2 3 4], dtype=int32, device=xpux:0))
访问和修改¶
我们可以直接对 Module 中的成员其进行访问,举例如下:
>>> model.bias
Parameter([0 0 1 1], dtype=int32, device=xpux:0)
通过这种方式访问的成员是可修改的:
>>> model.bias[0] = 1
>>> model.bias
Parameter([1 0 1 1], dtype=int32, device=xpux:0)
参见
相关接口:
parameters/named_parameters/buffers/named_buffers在下面的 Module 状态字典 小节中,以 BN 模块为例进行了更具体的对比;
警告
实际上这些接口会 递归地 获取模块中所有对应成员,参考 Module 嵌套关系与接口 。
Module 嵌套关系与接口¶
Module 之间通过嵌套会形成一个树形结构,例如下面这个最简单的嵌套形式:
实现代码
import megengine.module as M
class BaseNet(M.Module):
def __init__(self):
super().__init__()
self.linear = M.Linear(4, 3)
def forward(self, x):
return self.net(x)
class NestedNet(M.Module):
def __init__(self):
super().__init__()
self.base_net = BaseNet()
self.relu = M.ReLU()
self.linear = M.Linear(3, 2)
def forward(self, x):
x = self.base_net(x)
x = self.relu(x)
x = self.linear(x)
nested_net = NestedNet()
嵌套结构
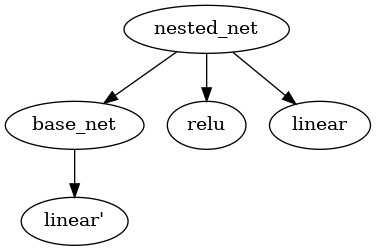
这样的树型结构有利于对结点进行遍历,此时 nested_net 作为根结点。
这里我们特意使用了相同的 linear 命名,注意它们并不会相互混淆:
一个是
nested_net.linear一个是
nested_net.base_net.linear
使用
children/named_children可以获取模块的直接孩子结点;使用
modules/named_modules可以 递归地 获取模块所有子结点。
>>> for name, child in nested_net.named_children():
... print(name)
base_net
linear
relu
>>> for name, module in nested_net.named_modules():
... print(name)
base_net
base_net.linear
linear
relu
如上述示例代码,通过递归遍历子结点,我们取得了 base_net.linear 模块。
访问嵌套 Module 成员¶
由于在嵌套结构中的每个结点都是一个 Module, 我们可以进一步访问其中的成员:
>>> for name, parameter in nested_net.base_net.named_parameters():
... print(name)
linear.bias
linear.weight
>>> nested_net.base_net.linear.bias
Parameter([0. 0. 0.], device=xpux:0)
但请注意,在 Parameter 与 Buffer 成员 提供的接口都是递归遍历 Module 结点的:
>>> for name, parameter in nested_net.named_parameters():
... print(name)
base_net.linear.bias
base_net.linear.weight
linear.bias
linear.weight
因此可以发现 base_net 中的 bias 和 weight 也被获取到了,该设计在大部分情况下非常有用。
注解
如果默认获取所有 Parameter 的逻辑不满足需求,也可以自行处理,如:
>>> for name, parameter in nested_net.named_parameters():
>>> if 'bias' in name:
>>> print(name)
base_net.linear.bias
linear.bias
这样可以仅对 bias 类型的参数进行一些操作,例如设置单独的初始化策略。
参见
参考官方提供的 Models
中的各种模型结构代码会加深对 Module 用法的理解。
改变 Module 结构¶
模块结构并非不可变的,我们能够对 Module 内部的子结点进行替换
(但需保证 Tensor 形状能对得上):
>>> nested_net.basenet = M.Linear(5, 3)
>>> nested_net
NestedNet(
(basenet): Linear(in_features=5, out_features=3, bias=True)
(relu): ReLU()
(linear): Linear(in_features=3, out_features=2, bias=True)
)
共享 Module 参数¶
当 Module 较复杂时,我们可以让两个 Module 共享一部分 Parameter ,
来达到如根据 BP 算法更新的 Tensor时, 只需要更新一份参数的需求。
我们可以基于 Parameter 名字找到目标参数,通过直接赋值的方式来实现 Module 间共享。
nested_net = NestedNet()
base_net = BaseNet()
for name, parameter in base_net.named_parameters():
if (name == "linear.weight"):
nested_net.base_net.linear.weight = parameter
if (name == "linear.bias"):
nested_net.base_net.linear.bias = parameter
转换训练与测试状态¶
我们约定,通过 train 和 eval 两个接口,
可以将 Module 分别设置为训练和测试状态(初始默认情况下是训练状态)。
这是因为一些已经提供的模块在训练和测试时会有不同的 forward 行为(如 BatchNorm2d )。
警告
如果在测试模型时忘记转换状态,会导致得到非预期的结果;
在切换模块训练和测试状态时,会同步调整其所有子模块的状态,参考 Module 嵌套关系与接口 。
Module 状态字典¶
在前面的小节,我们介绍了模块中的 Tensor 可分为 Parameter 与 Buffer 成员 两种:
>>> bn = M.BatchNorm2d(10)
>>> for name, _ in bn.named_parameters():
... print(name)
bias
weight
>>> for name, _ in bn.named_buffers():
... print(name)
running_mean
running_var
实际上,每个模块还有着一个状态字典 STATE_DICT 成员。可通过 state_dict 获取:
>>> bn.state_dict().keys()
odict_keys(['bias', 'running_mean', 'running_var', 'weight'])
STATE_DICT 中保存着所有可学习的 Tensor, 即不仅仅是 Parameter, 同时还有 Buffer.
我们可以通过 .state_dict()['key'] 的形式来进行访问字典中的信息:
>>> bn.state_dict()['bias']
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], dtype=float32)
看上去与直接访问成员没有什么用途上的区别,但是 ——
警告
Module 状态字典中 value 存放的数据结构类型为 numpy.ndarray, 且是只读的。
>>> bn.state_dict()['bias'][0] = 1
ValueError: assignment destination is read-only
参见
通过 load_state_dict 我们可以加载 Module 状态字典,常用于模型训练过程的保存与加载。
Optimizer中也有用于保存和加载的状态字典,参考 使用 Optimizer 优化参数 。关于模型训练过程中保存与加载的最佳实践,请参考 保存与加载模型(S&L) 。
注解
保存和加载 Module 状态字典时使用 ndarray 而不是 Tensor 结构,这样做是为了保证更好的兼容性。