使用 MegEngine Lite 部署模型¶
简介¶
MegEngine Lite 是 MegEngine 的一层接口封装,主要目的是为用户提供更加简洁、易用、高效的推理接口,充分发挥 MegEngine 的多平台的推理能力,其结构如下:
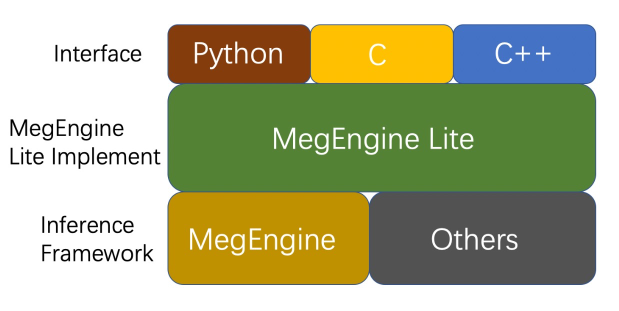
MegEngine Lite 主要是对训推一体的 MegEngine 框架进行一层很薄的封装,并对用户提供多种模型推理接口,包括: C++ / C / Python 接口,同时 MegEngine Lite 底层也可以接入其它的推理框架,以及其他的 NPU 支持。 相比较直接调用 MegEngine 的接口进行推理,使用 MegEngine Lite 的接口有使用方便、接口简单、功能齐全等优点, 其底层实现依然是 MegEngine, 因此继承了 MegEngine 的所有优点,MegEngine 在推理层面具有以下特点:
高性能¶
MegEngine 首先在计算图中对 Inference 做了很多高效的优化,例如: 将 BN 融合到 Convolution 中,将 Activation 融合到 Convolution 中等… 这些优化能有效地减少访存,提高计算访存比。 另外 MegEngine 还对底层的 Kernel 做了细粒度的优化,从算法到指令都进行深入优化, 卷积算法层面 Convolution 就有直接卷积,Im2col, Winograd 等优化, 在 Kernel 层面有粗粒度的 Intrinsic 级别的优化,在一些关键的算子会进行汇编,深入指令集优化。
多平台支持¶
MegEngine 支持多种主流深度学习推理平台,包括 Arm,X86,Cuda,Rocm,Atlas,Cambricom 等平台,另外 MegEngine Lite 还支持以 RuntimeOpr/Loader 的形式接入第三方推理框架以及NPU。
高精度¶
使用 MegEngine 训练的模型可以不需要进行任何模型转换,就可以直接进行推理, 有效地避免由于模型转换以及量化等带来的模型精度的损失,降低了模型部署的难度。