The device where the Tensor is located¶
Note
Generally, a graphics processing unit (GPU) is used instead of a central processing unit (CPU) as the main computing device during training. ( :ref:`construed <why-use-gpu>’)
By default, MegEngine will automatically use the fastest device currently available (xpux), **no additional manual designation is required. **
>>> megengine.get_default_device() 'xpux'
Among them,
xpumeansgpuorcpu, and the following ``x’’ means the number (if there are multiple devices), and the default starts from 0.
On a machine where no GPU device is detected, when MegEngine generates a Tensor for the first time, a reminder will be issued, as shown below:
>>> import megengine
>>> a = megengine.Tensor([1., 2., 3.])
info: ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
info: + Failed to load CUDA driver library, MegEngine works under CPU mode now. +
info: + To use CUDA mode, please make sure NVIDIA GPU driver was installed properly. +
info: + Refer to https://discuss.megengine.org.cn/t/topic/1264 for more information. +
info: ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
debug: failed to load cuda func: cuDeviceGetCount
debug: failed to load cuda func: cuDeviceGetCount
debug: failed to load cuda func: cuGetErrorString
>>> a.device
CompNode("cpu0:0" from "xpux:0")
对于日常的 MegEngine 使用情景,我们不需要关注冒号 : 后面编号的含义。’
Device related interface¶
The following are a few commonly used interfaces:
We can get the default computing node through: py:func:~.get_default_device;
We can set the default computing node through: py:func:~.set_default_device;
If you want to copy the Tensor to the specified computing device, you can use
copy.
With these interfaces, we can selectively perform Tensor calculations on the CPU or GPU. For example, designated as CPU:
>>> import megengine
>>> megengine.set_default_device("cpux")
>>> megengine.get_default_device()
'cpux'
>>> a = megengine.Tensor([1., 2., 3.])
>>> a.device
CompNode("cpu0:0" from "cpux:0")
由于指定了设备为 CPU, 则不会出现加载 CUDA 驱动失败的提醒。
See also
All the callable APIs can be found on the :ref:
The concept related to equipment is: Distributed Training.
Support GPU device and software platform¶
If you want to use the GPU device in MegEngine calculations, users do not need to perform additional coding. The framework will call the mainstream GPU software platform interface for users at the bottom layer. Therefore, users can focus on the design of the neural network structure and choose the performance optimization work that is believed to be done by the framework behind it. But if a user wants to become a MegEngine core developer or expand MegEngine functions, he needs to understand relevant background knowledge.
Warning
MegEngine default support the current mainstream Nvidia GPU device <https://developer.nvidia.com/cuda-gpus#compute> _ (Compute Capability 5.2 ~ 8.0), if within your device is not supported by the Nvidia GPU Compute Capability range, or need to use MegEngine support AMD GPU, need Build- from-source, otherwise it will trigger just-in-time compilation or report an error directly.
See also
Interested users can read the following explanations, skipping these parts will not affect the basic use of MegEngine.
Nvidia GPU and CUDA¶
Nvidia ` <https://en.wikipedia.org/wiki/Nvidia>` _ is a design GPU technology company, they created their own CUDA software platform and GPU hardware paired, so that developers can more easily build using the Nvidia GPU’s parallel processing capabilities of accelerated computing software. That is, Nvidia GPU is the hardware that supports parallel computing, and CUDA is the software layer that provides APIs for developers. Developers use it by downloading the CUDA toolkit, which comes with a dedicated library, such as cuDNN, the CUDA deep neural network library.
See also
You can use NVIDIA System Management Interface (nvidia-smi) to help manage and monitor NVIDIA GPU devices;
You can use the environment variable
CUDA_VISIBLE_DEVICESto limit the devices seen by the CUDA application. (Official blog)
AMD GPU and ROCm¶
Advanced Micro Devices (AMD) is a semiconductor company whose main products include microprocessors, motherboard chipsets, embedded processors and graphics processors. They provide the ROCm software platform to pair with their own GPU hardware, and their API design is very similar to CUDA.
Why do I need to use GPU training?¶
Before answering this question, we need to understand what is parallel computing <https://en.wikipedia.org/wiki/Parallel_computing> _ (Parallel Computing) - Parallel computing is a style of computing in which computing can be broken down into smaller independent calculation can be performed simultaneously, and then calculate The results are recombined or synchronized to get the result of the original calculation.
Serial computing
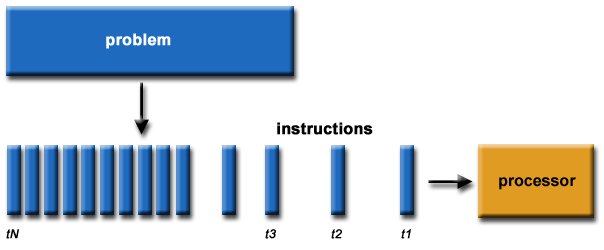
Parallel Computing
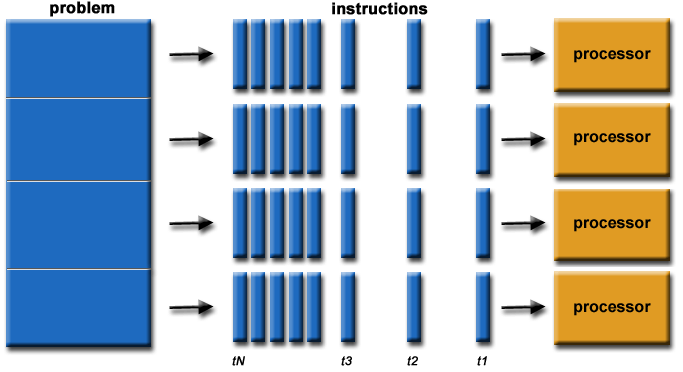
Graphic calculation means ` <https://en.wikipedia.org/wiki/Graphics_processing_unit>’_ (Graphics Processing Unit, the GPU) is a good at a particular processing apparatus (Specialized) type of computing, and the central processing unit’ <https://en.wikipedia.org/wiki/Central_processing_unit>’_ (Central Processing Unit, the CPU) is designed to deal with the general ( General) calculations. Although CPUs are capable of various complex computing operation scenarios, the highly parallel structural design of GPUs makes them more efficient than CPUs in processing parallel computing.
The number of tasks that a larger task can be decomposed into also depends on the number of cores (kernels) contained on the specific hardware. A core is a unit that actually performs calculations within a given processor. A CPU usually has four, eight, or sixteen cores, while a GPU may have thousands.
So we can conclude that:
The most suitable tasks for using GPUs are tasks that can be completed in parallel.
If calculations can be done in parallel, we can use parallel programming methods and GPUs to accelerate our calculations.
Using GPU is not necessarily faster!
The GPU can handle tasks that can be broken down into many smaller tasks very well, but if the computing task is already small, there may not be much benefit from moving the task to the GPU. Therefore, moving relatively small computing tasks to the GPU may not necessarily achieve significant speedups, and may even slow down.
In addition, the cost of moving data from the CPU to the GPU is high. If the calculation task is simple, the overall speed may slow down instead.
Parallelism in Neural Network Computing¶
There are a large number of parallel computing tasks in neural networks, some of which belong to Embarrassingly parallel, that is, each independent thread is embarrassed and unwilling to communicate with other threads. In fact, it describes that each thread can independently complete parallel computing tasks without communicating. From a semantic point of view, such parallel computing is easy, perfect, and even pleasant.
A typical example is-Convolution (Convolution) operation.
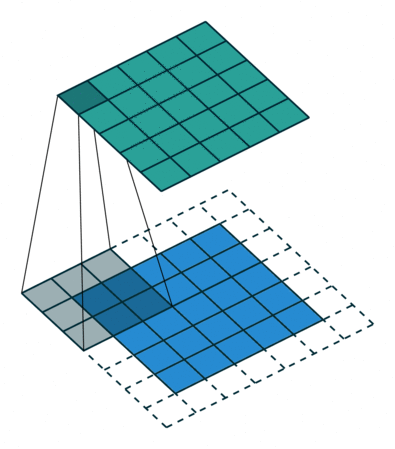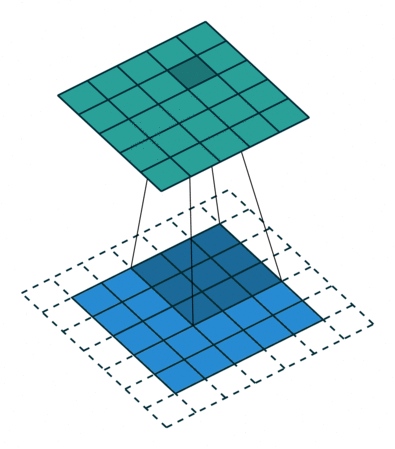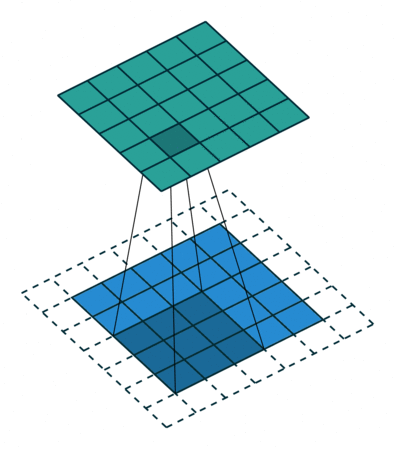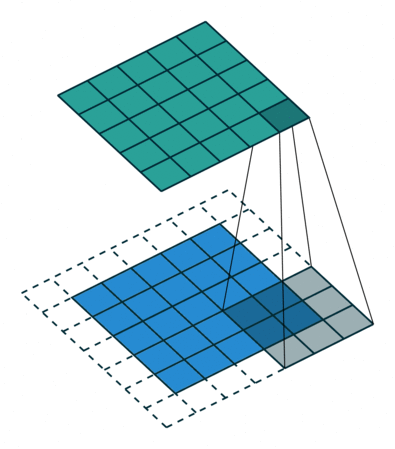
The above figure is an example. The blue part (bottom) in the figure represents the input channel, the shade on the blue part represents the \(3 \times 3\) convolution kernel, and the green part (top) represents the output channel. For each position on the blue input channel, a convolution operation is performed, that is, the shaded part of the blue input channel is mapped to the corresponding shaded part of the green output channel.
These calculations occur one after another, but each calculation is independent of other calculations, that is, does not depend on the results of other calculations;
Therefore, all these independent calculations can be performed in parallel on the GPU, and finally the entire output channel is generated.
GPGPU computing¶
GPU was originally used to accelerate specific calculations in computer graphics, so it was named “graphics processing unit”. But in recent years, more kinds of parallel tasks have appeared. As we have seen, one of the tasks is deep learning. Deep learning and many other scientific computing tasks that use parallel programming techniques are giving birth to a <https://en.wikipedia.org/wiki/General-purpose_computing_on_graphics_processing_units>`_, GPGPU).
Note
GPGPU computing is more commonly referred to as GPU computing or accelerated computing, because it is becoming more and more common to perform various tasks on the GPU.