Deploy the model with MegEngine Lite¶
Introduction¶
MegEngine Lite is a layer of interface encapsulation of MegEngine. The main purpose is to provide users with a more concise, easy-to-use and efficient reasoning interface, and give full play to the multi-platform reasoning capabilities of MegEngine. Its structure is as follows:
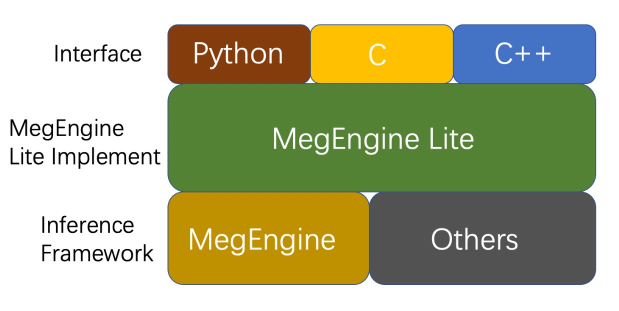
MegEngine Lite mainly encapsulates the MegEngine framework integrated with training and pushing in a thin layer, and provides users with a variety of model inference interfaces, including: C++ / C / Python interfaces, and the bottom layer of MegEngine Lite can also access other inference frameworks , and other NPU support. Compared with directly calling the interface of MegEngine for reasoning, the interface using MegEngine Lite has the advantages of convenient use, simple interface and complete functions. Its underlying implementation is still MegEngine, so it inherits all the advantages of MegEngine. MegEngine has the following characteristics at the inference level:
high performance¶
MegEngine first made a lot of efficient optimizations on Inference in the calculation graph, such as: fused BN into Convolution, Activation into Convolution, etc. These optimizations can effectively reduce memory access and improve the computing memory access ratio. In addition, MegEngine has also made fine-grained optimization to the underlying Kernel, in-depth optimization from algorithms to instructions. Convolution at the convolution algorithm level includes direct convolution, Im2col, Winograd and other optimizations. At the Kernel level, there are coarse-grained Intrinsic level Optimization, in some key operators will be assembled, in-depth instruction set optimization.
Multi-platform support¶
MegEngine supports a variety of mainstream deep learning inference platforms, including Arm, X86, Cuda, Rocm, Atlas, Cambricom and other platforms. In addition, MegEngine Lite also supports access to third-party inference frameworks and NPUs in the form of RuntimeOpr/Loader.
High precision¶
Models trained with MegEngine can be directly inferred without any model conversion, which effectively avoids the loss of model accuracy due to model conversion and quantization, and reduces the difficulty of model deployment.