MegEngine Virtual Alchemy Challenge¶
What this tutorial covers
Improve the convolutional neural network model in the previous tutorial and understand the official implementation of ResNet in the MegEngine/Models library;
Learn how to save and load models, and how to use pretrained models for inference;
Integrate common skills in model development, summarize this series of tutorials, and provide several possible learning directions for reference.
Warning
The style of this tutorial is rather unique. Suppose you are using MegEngine to participate in a competition, and I hope you can get the feeling of being there;
We don’t end up actually training a ResNet model from scratch (it took too long), but rather mastering the idea.
See also
Most of the demo code comes from: official/vision/classification/resnet (our purpose is to read it)
ImageNet dataset¶
Recall that in the previous tutorials, our explanation ideas are similar, there are a lot of repeated code patterns:
Usually we introduce a simple model and implement it, then use it on the dataset for the current tutorial;
In the next tutorial, we just switched to a more complex dataset and found that the model did not work well;
Therefore, it is necessary to design a better model (taking the opportunity to introduce new relevant knowledge), and train and verify it.
In step 2, what we need to modify is mainly the data loading part, such as calling different dataset acquisition interfaces; in step 3, data loading is no longer a concern, we focus on model design and hyperparameters Adjustment. In fact, for the same type of task, the same model design may be used for different datasets, and even just a little fine-tuning in the last trained model can achieve good results in similar tasks. This makes people think - how to optimize the model development process so that it can be more efficient in the face of different tasks?
This tutorial will also help you to think about some modularity and engineering issues, and to get in touch with possible workflows in production.
Learn about dataset information¶
ImageNet 数据集与 ILSVRC
ImageNet 1 has 14,197,122 images and 21,841 synset indexes. A subset of this dataset is used in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) as a benchmark for image classification and object detection. The term “ILSVRC” is sometimes used to specifically refer to the dataset used in the competition (ie, a subset of the ImageNet just mentioned), the most commonly used one is the 2012 dataset, denoted as ILSVRC2012. Therefore, it is sometimes referred to as By ImageNet, probably referring to this subset of ImageNet used for ILSVRC2012.
ResNet in MegEngine/Models is trained and evaluated on the ILSVRC2012 dataset by default. In ILSVRC2012, there are more than 1.2 million images as the training set, 50,000 images as the validation set, and 100,000 images as the test set (without labels). There are 1000 categories in total. ILSVRC2012 is sometimes called ILSVRC 1K, where 1K refers to 1000 categories.
We have mentioned the concept of data set division in the previous tutorial, ILSVRC is a good example, the competition will provide you with marked training set and validation set, but the test set is actually used for ranking . Participants do not have any way to obtain the marks corresponding to the test set, and can only submit the prediction results of their own models on the test set to the competition platform, and the back-end machine judges will evaluate the final results in combination with the marks of the test set (the evaluation indicators are public of). In the scientific literature, it is common to compare evaluation results on training and validation sets.
The ResNet model won the championship of ILSVRC in 2015, and its design ideas have been verified by time, which can be described as a classic.
Warning
The most frequently used ILSVRC2012 image classification and localization dataset is currently available at Kaggle <https://www.kaggle.com/c/imagenet-object-localization-challenge/overview/description>. However, the complete ImageNet and other commonly used subsets cannot be obtained directly. Although MegEngine provides the corresponding :class:`~.ImageNet processing interface, it is only used for processing local data, not the original data set. download.
ImageNet evaluation metrics
Top-1 accuracy rate:predicts the classification probability, the category with the highest probability is consistent with the real mark, that is, it is considered correct;
Top-5 Accuracy:In the predicted classification probability, the top five categories in the probability contain the true marked category, that is, it is considered correct.
This corresponds to the topk_accuracy interface in MegEngine, or 1 - correct rate if expressed in error rate.
Attend Virtual ILSVRC¶
Go back to 2015 in the parallel universe. As a member of the MegEngine alchemy furnace team, you just learned the convolutional neural network. Originally, you tried to use the LeNet5 model to participate in the ILSVRC competition. Look. Returning without a feather is definitely not the team’s goal, and paddling sightseeing is even more unacceptable. Now we need to find ways to improve it and strive to play a good role in this year’s challenge.
Kaiming, Xiangyu and Shaoqing have decided to join your team. The experienced teacher Sun Jian will serve as a guide to participate in the ILSVRC2015 Challenge!
真实情况是…
He Kaiming, Zhang Xiangyu, Ren Shaoqing and Sun Jian are the authors of the paper “Deep Residual Learning for Image Recognition”, yes, this is the corresponding paper of the ResNet model, which won the CVPR 2016 Best Paper.
Note:CVPR is an acronym for Conference on Computer Vision and Pattern Recognition. As an annual academic conference of IEEE, the main content of the conference is computer vision and pattern recognition technology. CVPR is the world’s top computer vision conference, you can try to use MegEngine to reproduce the experimental results in many classic papers.
The following plots will be quite different (fictional) from the actual history, and will be explained in this way.

So the question is, how to improve it? The idea of solving problems is very important, and everyone decides to think about solutions from different angles.
Mr. Sun said:”Let’s first take a look at what the ILSVRC image classification champion and runner-up in the past few years can provide.”
The related papers Xiangyu has already been thoroughly familiar with, and soon he gave several papers that need to be focused on:AlexNet, VGGNet, GoogleNet… “The processing ideas and model structures of these papers are quite novel and worthwhile. Take a look.” So everyone decided to start with AlexNet in chronological order.
Increase the firepower of alchemy¶
Traditional neural network uses sigmoid or tanh as activation function, AlexNet uses relu, which you have already applied. Also you noticed that AlexNet uses 2 GPUs for training! “We need more GPUs to save time!” you exclaim excitedly.
真实情况是…
Using multiple GPU devices involves the concept of Distributed Training, which really saves time compared to single-card training. But in the historical background at that time, the actual reason why the author Alex Krizhevsky used two GPUs was that the memory of the GPU device (GTX 580) used at that time was not enough to store all the parameters in AlexNet, so the drawn model structure is such:
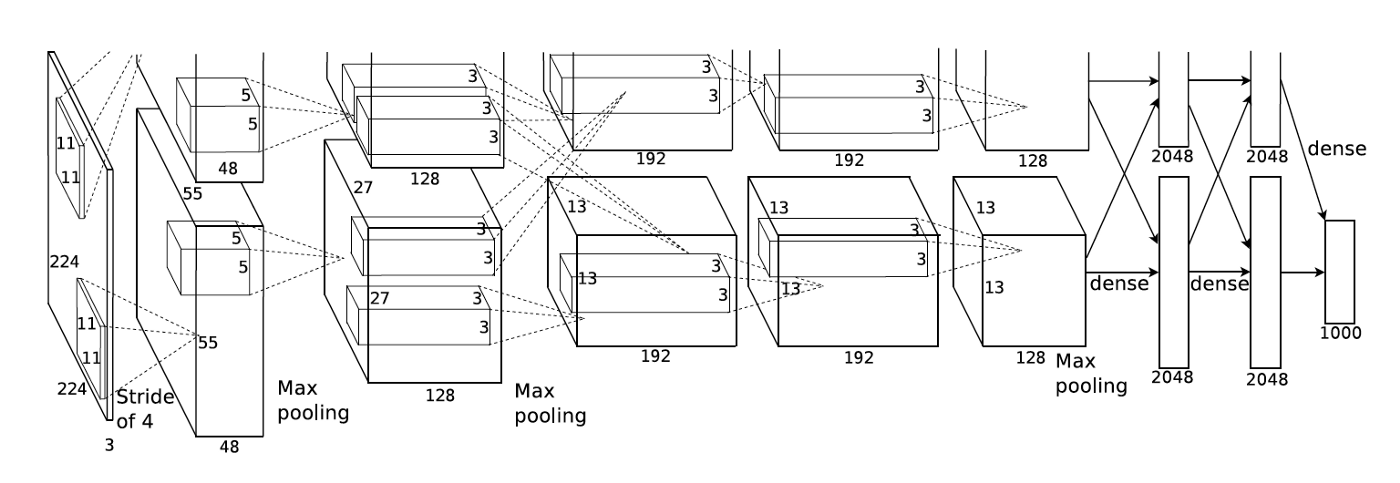
From the paper `ImageNet Classification with Deep Convolutional Neural Networks <https://www.cs.toronto.edu/~kriz/imagenet_classification_with_deep_convolutional.pdf>¶
Today’s GPU devices have enough memory to hold a complete AlexNet structure, which can be reproduced on most single-card GPUs. But AlexNet is the first experiment to use GPU to accelerate neural network computing, so its historical significance is extraordinary, it marks the arrival of a new era, as the so-called “alchemy uses GPU, dare to teach the sun and the moon to change the sky.” Infeasible network computing is now the norm. great! sigh!
See also
In official/vision/classification/resnet/train.py#L112 supports single or multiple GPUs for ResNet training, where each GPU device is seen as a worker. Multiple GPU devices for training When you need to pay attention to various data synchronization strategies, such as:
# Sync parameters and buffers
if dist.get_world_size() > 1:
dist.bcast_list_(model.parameters())
dist.bcast_list_(model.buffers())
# Autodiff gradient manager
gm = autodiff.GradManager().attach(
model.parameters(),
callbacks=dist.make_allreduce_cb("mean") if dist.get_world_size() > 1 else None,
)
From single card to multi-card, you need to use launcher decorator. For more introduction, please refer to Distributed Training .
I saw Teacher Sun wave:with a big hand, “No problem, I’ll give you eight cards with excellent physique and strong performance. Let’s fill up the firepower.”
Improve the quality of spiritual materials¶
You are indulging in the whimsy of Doka’s magic, at this time Shaoqing reminds everyone:”AlexNet has also done data enhancement, we can try it too.”
data augmentation¶
As the saying goes, “informed and well-informed”, larger datasets usually lead to better model performance, so data augmentation is a very common preprocessing method. However, the ImageNet competition does not allow the use of other data sets, so the approach that can be taken is to perform some random processing on the pictures in the original data set, such as random translation, flipping and so on. To the computer, such pictures can be seen as different, and random factors make each batch of data different. For example, the effect is as follows:

The data.transform module of:implements common image data transformations, which can be performed when loading data.
train_dataloader = data.DataLoader(
train_dataset,
sampler=train_sampler,
transform=T.Compose(
[ # Baseline Augmentation for small models
T.RandomResizedCrop(224),
T.RandomHorizontalFlip(),
T.Normalize(
mean=[103.530, 116.280, 123.675], std=[57.375, 57.120, 58.395]
), # BGR
T.ToMode("CHW"),
]
)
)
“Okay, this way you can randomly crop the length and width to 224 when loading data, and randomly flip horizontally.” Shaoqing quickly checked MegEngine’s API documentation and added these operations steadily. At the same time, he is also doing the normalization of Normalize, marking the channel order of the picture, “Good habit, this wave is really learned”, you silently gave a thumbs up in your heart .
真实情况是…
The data augmentation operations used in AlexNet are somewhat different from here, corresponding to the transform.Lighting interface.
The data enhancement method demonstrated here is to use the interface of MegEngine to transform and process the data immediately after loading, which is also called online enhancement. In some scenarios, we can also use offline enhancement to the data, that is, to do enhancement processing in advance with software such as OpenCV, so that when loading the data, it can be regarded as using several datasets. This method needs to take up more space, and the online enhancement only randomly processes the data of the current Batch each time, and it is no longer needed when it is used up.
Adding data from the validation set (or even the test set, if you can get it) to the training set does not count as data augmentation, but rather data leakage, and your model may overfit on these datasets.
Data cleaning¶
In addition to data enhancement, you also think of a possibility:”Is there a problem with the quality of ImageNet’s own dataset?”
The content and labeling quality of the data will have an irreparable impact on the effect of the model. Since ImageNet is essentially a network image dataset, there will be a lot of dirty data in it - the image content is of poor quality and the format is inconsistent (grayscale image). mixed with color images), labelling errors, etc. You become a data cleaning expert and try to manually clean these dirty data, but the efficiency is too low, so you give up rationally.
See also
In fact, there are already many good data cleaning tools that can help us do similar work, such as `cleanlab <https://github.com/cleanlab/cleanlab>can help us find the wrong labels in the dataset, its official statement found close to 100,000 errors in the ImageNet dataset mark!
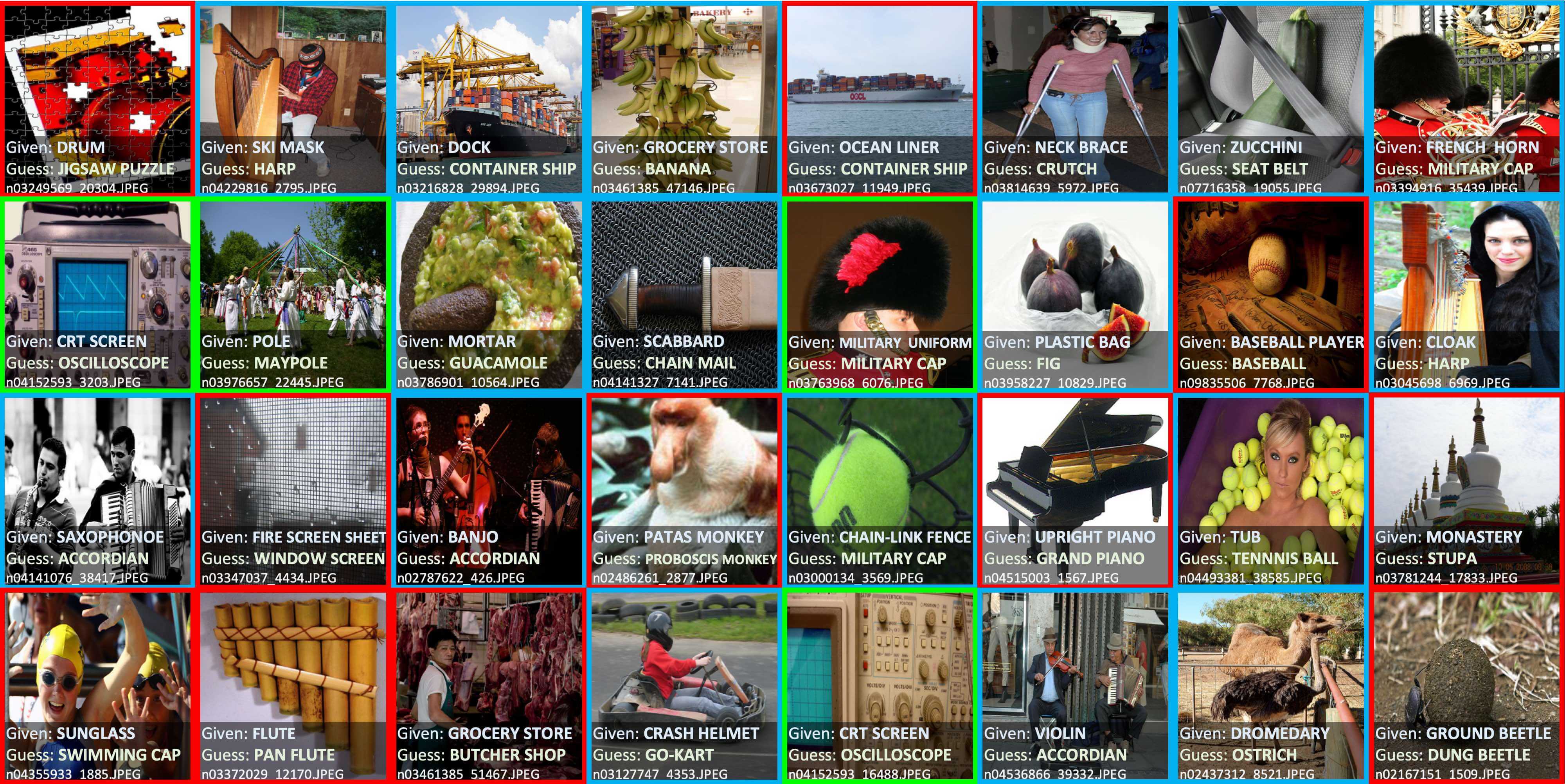
Top label issues in the 2012 ILSVRC ImageNet train set identified using cleanlab. Label Errors are boxed in red. Ontological issues in green. Multi-label images in blue.¶
In industry, you will see in some machine learning teams there are dedicated data teams responsible for improving dataset quality. Long live the cooperation!
Secret high-end pill recipe¶
After you and Shaoqing were busy with data-related processing, simply compared the experimental results, and it did increase by a few points, effective! But this can only be regarded as standing on the same starting line as others. After all, similar operations can be used by everyone, and there is nothing special. Then everyone began to study the differences between the AlexNet and LeNet5 models. You found that Dropout is used in AlexNet to prevent overfitting. Its idea is very simple: randomly “drop” some neurons in each iteration, making it inactive and not participating in the calculation process come. In other words, it can also be understood that only a part of the neurons are trained during each training, which is ultimately equivalent to multiple weak classifiers being bagged together to perform work.
“But there are fewer neurons in the convolution kernel than the fully connected layer, so the benefits of using Dropout are not so obvious.” Kai Ming murmured a few words.
Batch Normalization¶
Everyone decided to continue thinking about the data feature level. When inputting data, a transform.Normalize normalization is usually performed, which can make the feature distribution of the data more uniform and accelerate the convergence. However, there must be differences between the data, and the update of the parameters of the hidden layer in the neural network will cause the distribution of the output data to change. With the increase of the number of layers, this offset phenomenon will be more serious. “If the essence of the neural network is to learn the distribution of data, after the calculation of the hidden layer makes the data distribution change, it has to learn the changed distribution, which may cause the training to be unstable and difficult to converge.” Kai Ming raised doubts. At this time, Xiangyu added: “I remember that the model structure of VGGNet is as deep as 19 layers, but if it continues to deepen, it will be difficult to achieve better results.” Then he showed the model structure in the VGGNet paper.:
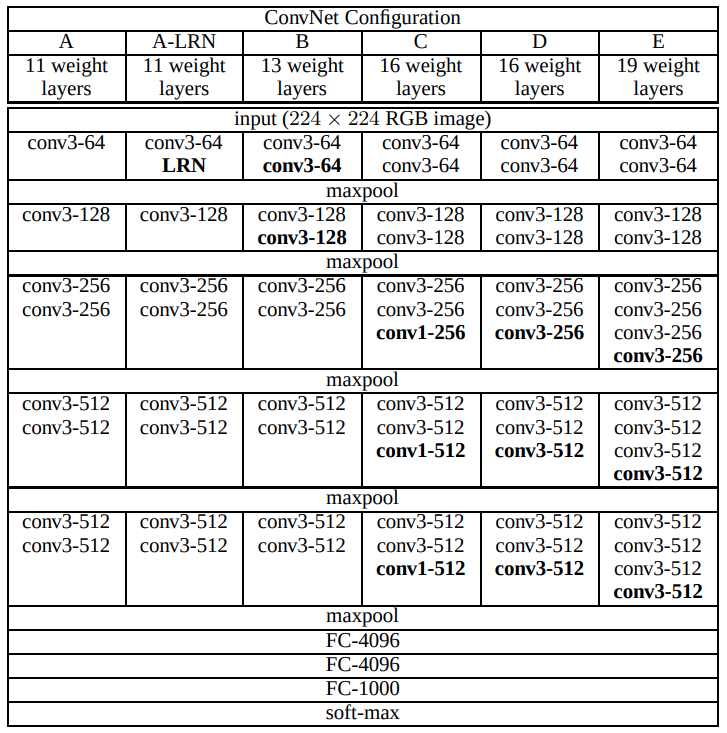
VGGNet configuration, from the paper “Very Deep Convolutional Networks for Large-Scale Image Recognition”¶
“In addition to the deeper structure, the difference between it and AlexNet is that the kernel_size of the convolution is not as large as that of AlexNet, and it is uniformly changed to a fixed \(3 \times 3\) convolution kernel, and some places are \(1 \times 1\).” You take a closer look and think about the discussion about data just now.
Teacher Sun gave suggestion:at this time, “Since normalization is useful in preprocessing, you should also do the same after each layer changes. Wouldn’t it help?” Xiangyu immediately began to write code, in Conv2d After the layer is calculated, the mean and variance are calculated based on the current Batch data, and the Normalize operation is performed. Then add this interface to MegEngine, named BatchNorm2d.
After adding the BN layer to VGGNet, although each Epoch has more calculations, the entire training process converges faster, and finally it really increases!
真实情况是…
Batch Normalization actually comes from the paper “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift” by Sergey Ioffe and Christian Szegedy. Just because it is used in the ResNet model, some settings are imposed here. BN does have the effect of speeding up training stability, convergence speed, and preventing overfitting in practice. The initial framework has no ready-made interface, so researchers need to implement the calculation and backpropagation logic of BN by themselves. (At that time, Zhang Xiangyu was the person with the strongest coding skills among ResNet authors, and also knew CUDA and was responsible for the underlying framework and coding implementation.)
For more information about BN, please refer to the following video:
Note
The producer of this video is researcher Wang Feng from MegEngine Researcher, and the software used is Manim. Readers are welcome to make more similar short videos, and I am happy to use them as supplementary knowledge in MegEngine documentation and tutorials .
More explanation on Batch Normalization
Once a popular explanation is that Batch Norm can solve the internal covariate shift (Internal Covariate Shift) phenomenon that exists in deep neural network training, but later related papers have proved that this conclusion is not valid. Therefore, BN has become more of a commonly used technique (Trick). There are many similar techniques in the field of deep learning that have not received rigorous theoretical support, and many scholars are studying the interpretability of neural networks. The development of things is always an upward spiral, and there may be no permanent theory (which may be overturned in a larger framework), but there are theories that are useful in the moment. Practice is the only criterion for testing truth, and the field of deep learning still needs people to think and practice more, waiting for the arrival of theoretical explanations.
Likewise, after using BatchNorm2d, Dropout can usually be dropped (this is also a practical experience).
还有的真实情况是…
There is indeed a practical explanation for changing the big Kernel into a small Kernel in VGGNet, but just like the discussion between big data and small data, large model and small model, there is currently no strict theory to prove that small Kernel It must be more effective than the large Kernel. In other words, from some other aspects, perhaps the large Kernel will be more suitable than the small Kernel in certain situations.
Ideas in published papers without rigorous mathematical proof are likely to be superseded by new ideas in the future. Therefore, when reading a paper, it is more necessary to substitute into the author’s environment at that time, and understand the author’s idea of solving problems under the experimental conditions and background at that time.
See also
In the VGG model code of BaseCls, you can see the VGGNet with BN layer and the VGGNet model without BN layer.
Fantastic initialization strategy¶
Everyone realizes that the:neural network has to continue to deepen if it wants to improve its ability, but it is difficult to converge if it is deepened. The improvement of BN is only a small step.
One day in the middle of the night, the MegEngine alchemy furnace WeChat group suddenly received a message from Xiangyu:”I have a idea!” Then after ten minutes, a few more pictures came from the group. Scribbled handwritten draft. Xiangyu mentioned:”I made some assumptions of independence and introduced a set of parameter initialization rules. Do you want to try it!” Sure enough, after verification, after using Xiangyu’s initialization strategy, the overall effect became better. You just wanted to send an emoji to celebrate, but Kaiming, Shaoqing, and Teacher Sun all used WeChat to pat Xiangyu’s “Paper that hasn’t been read yet”, saying, “We haven’t slept yet.”
Then… strike while the iron is hot. Everyone started the research together again, and designed a new activation function prelu to model nonlinear features and deduce a theoretical initialization method. You applied your new method to the competition, and the result reduced the error rate to 4.94%. This has surpassed the level of human recognition image classification (5.1% error rate), which is something that Google failed to do in 2014! Their best score is only 6.67%!
for m in self.modules():
if isinstance(m, M.Conv2d):
M.init.msra_normal_(m.weight, mode="fan_out", nonlinearity="relu")
if m.bias is not None:
fan_in, _ = M.init.calculate_fan_in_and_fan_out(m.weight)
bound = 1 / math.sqrt(fan_in)
M.init.uniform_(m.bias, -bound, bound)
elif isinstance(m, M.BatchNorm2d):
M.init.ones_(m.weight)
M.init.zeros_(m.bias)
elif isinstance(m, M.Linear):
M.init.msra_uniform_(m.weight, a=math.sqrt(5))
if m.bias is not None:
fan_in, _ = M.init.calculate_fan_in_and_fan_out(m.weight)
bound = 1 / math.sqrt(fan_in)
M.init.uniform_(m.bias, -bound, bound)
See also
The relevant implementations correspond to msra_normal_, init module.
真实情况是…
The work of RPeLU and MSRA initialization was published in the paper “Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification”. According to the title, it can be found that the impact of this work was unique at the time.
At that time, several authors of ResNet were working in Microsoft Research Asia (MSRA). Internally, this initialization method was called “Xiangyu” initialization, but then He Yuming went to work on FaceBook. FaceBook’s deep learning framework PyTorch named the interface ` kaiming_uniform_` and kaiming_normal_. This is also an anecdote. Zhang Xiangyu later came to Megvii Research Institute. As the deep learning framework of Megvii Technology, MegEngine can also provide xiangyu_uniform_ and ` xiangyu_normal_` interface, but in order to avoid cognitive burden, and it is not common to use person’s name as an interface, the MSRA initialization name is finally chosen.
(PS:WeChat shoot function will be launched in 2020, so the plot of this piece is obviously deliberately fictitious.)
(PPS:If you don’t know which company FaceBook is, you can search for its new name - META.)
The birth of residual connections¶
Breaking the record is gratifying, but the challenge has slowly turned into an engineering problem. Xiangyu said seriously:”Actually, I am personally very dissatisfied, because although defeating humans, it is more of a gimmick. We also know that these methods are not very work, mainly relying on parameter tuning and stacking models.”
So Xiangyu replayed the game again. He found that the 2014 ImageNet champion Google GoogLeNet model was not very complicated, but achieved a very high accuracy rate. “GoogLeNet may be the only way for several other models.” In his eyes With a firm gaze. After several months of research, Xiangyu found that the essence of GoogLeNet is its 1x1 shortcut. “To put it bluntly, simplifying it to the simplest, you can find that GoogLeNet has only two paths, one is 1×1, the other is The way is a 1x1 and a 3x3.”
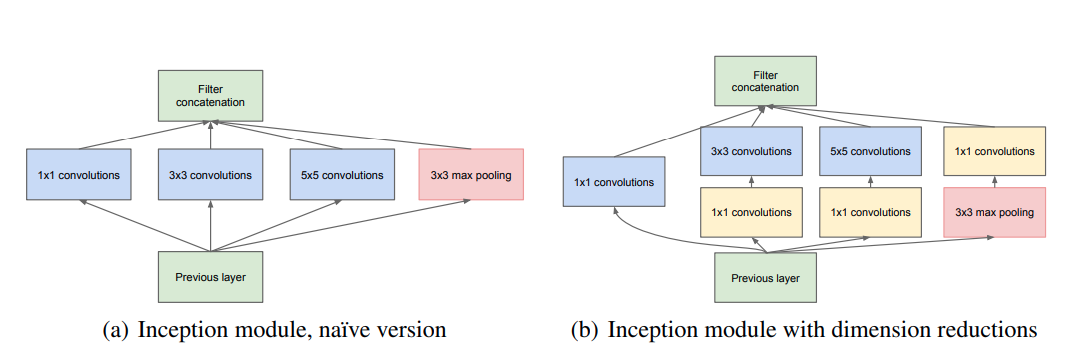
Inception module in GoogLeNet, picture from “Going Deeper with Convolutions”¶
“What is it that supports such high performance of GoogLeNet at very low complexity?”
Xiangyu conjectured that its performance is determined by its depth, and in order for the GoogLeNet 22-layer network to be successfully trained, it must have a short enough straight path. Based on this idea, Xiangyu began to design a model, using a structural unit to continuously divide it up. Although the structure of the model will be very complicated, no matter how complicated it is, it will always have a way, but the depth can be very deep. Xiangyu found his teammates and shared this point of: . “I think this structure can maintain sufficient accuracy and is also very good for training. I call this network a fractal network.”
But Kaiming felt that the:structure was still too complicated. “Complex things often don’t get the essence.”
Kaiming suggests further simplification of this model, using a simplified form of it. So Xiangyu extended the previous assumption: “The shortest path determines the degree of easy optimization; the longest path determines the ability of the model, so can the shortest path be as short as possible to zero layers? Put the deepest path as short as possible. The path becomes infinitely deeper?” Based on this idea, there is a path without any parameters, and it can be considered that the model structure with the number of layers is 0 was born - ResNet.
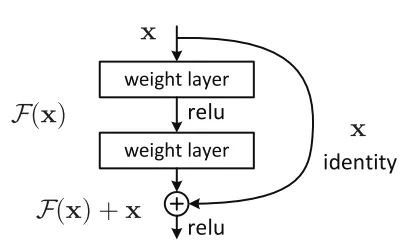
Residual connection in ResNet, picture from “Deep Residual Learning for Image Recognition”¶
The teammates decided to let you implement the model structure of ResNet, you put the implementation code in official/vision/classification/resnet/model.py
The logic of the forward calculation of the residual connection is concise and elegant, and the reverse derivation process will be automatically completed by:.
def forward(self, x):
identity = x
x = self.conv1(x)
x = self.bn1(x)
x = F.relu(x)
x = self.conv2(x)
x = self.bn2(x)
identity = self.downsample(identity)
x += identity
x = F.relu(x)
return x
With this basic structure, you start trying to deepen the network and train it to see if it works as expected.
18 layers, 34 layers… Compared with the ordinary structure, the Top-1 error rate obtained on the validation set has decreased by 3.5%, and the residual connection can converge and continue to deepen! 50 layers, 101 layers, the effect is still getting better! In the end you stopped at the 152-layer structure… and submitted the test results to the competition platform.
The final result of the ILSVRC’15 classification challenge is out, the Top-5 score of BN-inception (Google’s improved GoogLeNet) on the ImageNet test set is 4.82, and the final score of ResNet is - 3.57! Your morale is soaring, Won first place in 5 challenges using ResNet. Under the guidance of Mr. Sun, you submitted your ResNet paper to CVPR 2016 and won the best paper award!
“Mr. He Yuming’s research ideas have inspired me a lot, finding out the essential attributes of the most work from the complicated structure. This extremely simplified idea is the core of ResNet, and makes ResNet have a strong generalization ability. Various modifications can be made on the basis, which can inspire other people’s research.” Xiangyu said. Later, Xiangyu and Mr. Sun went to a start-up company in China, determined to build the strongest computer vision research institute in the Eastern Hemisphere. Kaiming went to a technology giant in the United States to engage in his own research work. Shaoqing decided to join the field of autonomous driving… After you have the experience of this competition, you will be more comfortable using MegEngine, whether it is scientific research or engineering, you are full of confidence, and everyone has a bright future.
真实情况是…
The plot described here refers to the article “Sun Jian’s First Deep Learning Ph.D. Zhang Xiangyu Reads 1,800 Papers in 2003, and Takes the Helm of:Basic Model Research at the Age of 28”. Some of the contents have been modified, and most of them are based on real historical background. There are many variants of ResNet, and the idea of residual connection proposed among them has been seen everywhere in the streets and alleys of the “deep learning” magic world.
Improve fire control technology¶
During the competition, you also used common tricks related to model optimization algorithms. For example, for the SGD optimizer, you used the weight decay technique and introduced the momentum (Momentum) (the meaning of these parameters can be found in the documentation):
# Optimizer
opt = optim.SGD(
model.parameters(),
lr=args.lr * dist.get_world_size(),
momentum=args.momentum,
weight_decay=args.weight_decay,
)
When using these techniques, the specific heat is always difficult to control, and the elixirs are always grotesque. But Jiang was still old and hot. Teacher Sun had seen this situation all the time. He drank:in a deep voice, “Tune!”, and then used his inner strength to remind him that the medicinal pill was slowly taking shape in the flame of the pill stove. The rest of the people were overjoyed. Mr. Sun wiped the sweat from his forehead, took out a “Gradient Descent Sunflower Collection”, and said: “There is a lot of practice and theory of optimization algorithms. This is a review. Please study it when you have time.”
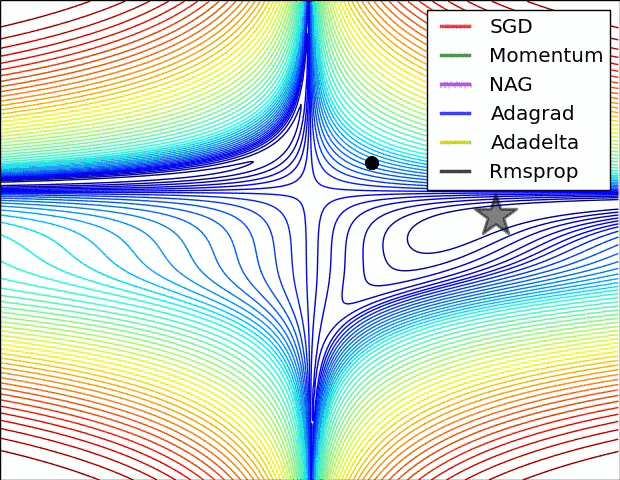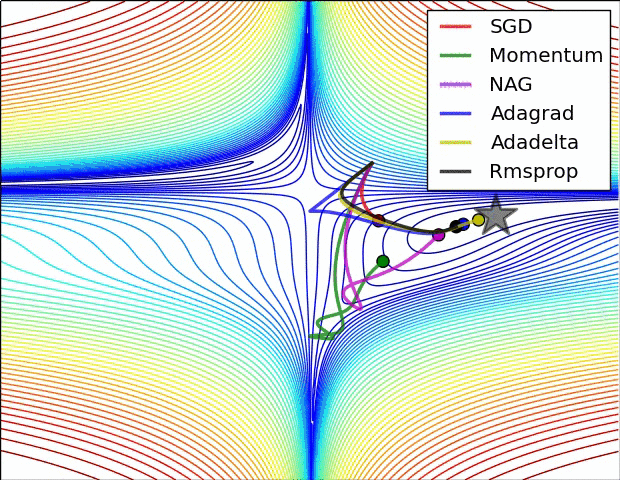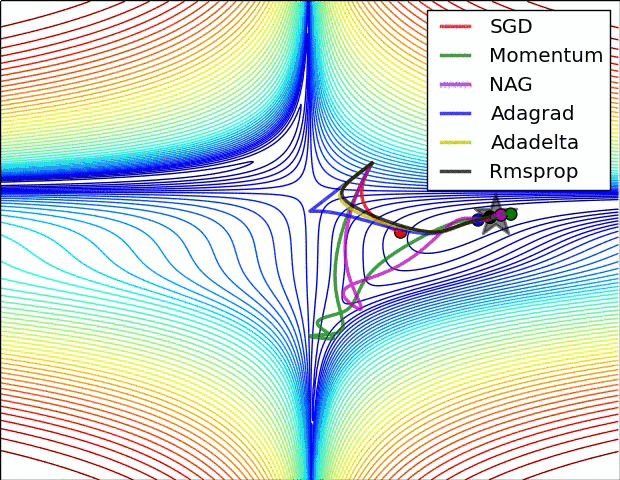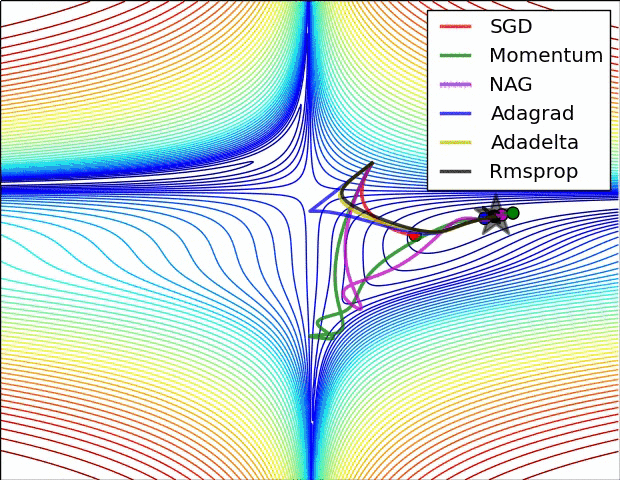
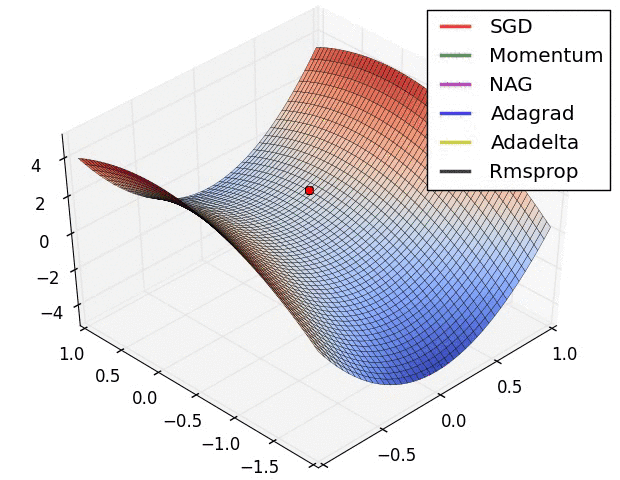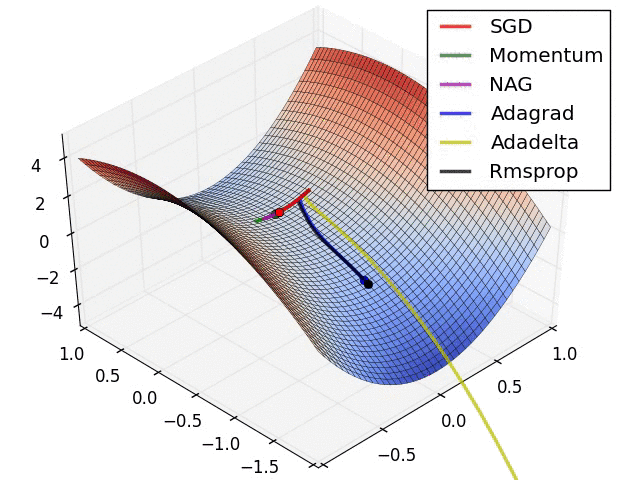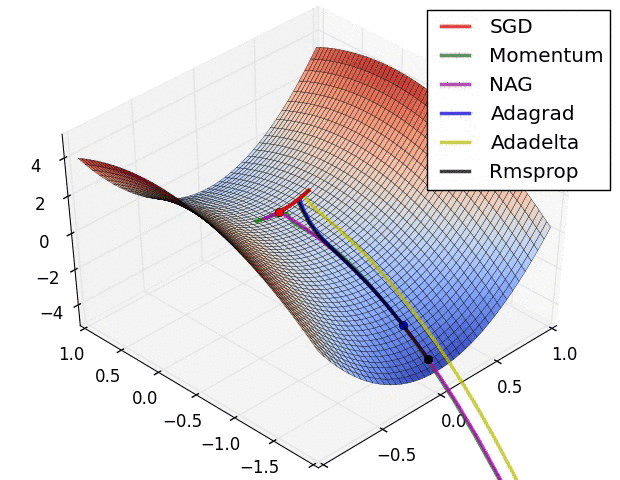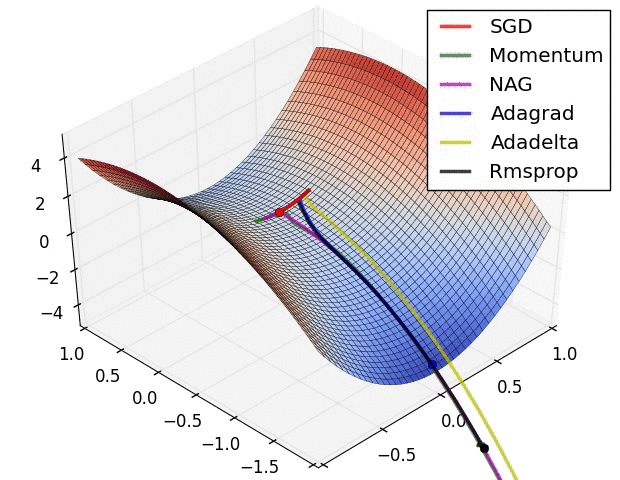
真实情况是…
“An overview of gradient descent optimization algorithms” is an article hanging on Arxiv, the original form is a blog, published in 2016, only some improvements of SGD are mentioned here. But some of these optimization methods, such as Momentum, have been proposed and improved continuously from 2013 to 2015. The optimizer modules in MegEngine implement common optimizers, such as SGD, Adam, etc. Its functions can be flexibly expanded according to actual needs, and users can design optimization algorithms by themselves .
There is still no conclusion on which optimization algorithm is better or worse, and there seems to be a rule to follow in the adjustment of the learning rate, which will affect the convergence of the model.
Postpartum care of elixirs¶
In the field of deep learning, it is very common for researchers to reproduce experimental results in other people’s papers. For a research paper, if the original author does not provide the source code of the experiment, then others can only try to reproduce it by themselves, which may lead to huge differences in the final experimental results due to some differences in details. Even if the source code of the model structure and the training and testing process is provided, it will take a considerable amount of time for others to obtain the same model, and may get different results due to random states in some codes. Therefore, most people publish their research results in order to facilitate others to reproduce the experimental results. The model file will be published along with the pre-trained model parameter file for others to verify.
See also
There are many cutting-edge experimental results and supporting codes on the website Paper with code, you can try to reproduce with MegEngine for reference;
About how to Save and Load Models (S&L) locally, it has been introduced in detail in the user guide, so I won’t repeat it here;
In order to facilitate users to quickly obtain pre-trained models, MegEngine also provides
hubmodule, which can be used to share and download trained models through GitHub/GitLab, which is convenient for researchers to use, refer to Use Hub to publish and load pre-trained models .
Let’s use the Hub to get the pre-trained ResNet18 model from MegEngine official:
import cv2
import numpy as np
import megengine
import megengine.data.transform as T
import megengine.functional as F
import megengine.hub as hub
image_path = "/path/to/example.jpg" # Select the same image to read
image = cv2.imread(image_path)
transform = T.Compose([
T.Resize(256),
T.CenterCrop(224),
T.Normalize(mean=[103.530, 116.280, 123.675],
std=[57.375, 57.120, 58.395]),
T.ToMode("CHW"),
])
model = hub.load('megengine/models', 'resnet18', pretrained=True)
model.eval()
processed_img = transform.apply(image) # Still NumPy ndarray here
processed_img = F.expand_dims(megengine.Tensor(processed_img), 0) # -> 1CHW
logits = model(processed_img)
probs = F.softmax(logits)
print(probs)
The input data needs to be preprocessed accordingly (and the channel order needs to be consistent);
Remember to switch the loaded pre-trained model to evaluation mode through the
evalinterface;The input accepted by the model should be Tensor input (for some models, ndarray will be automatically converted to Tensor).
This allows us to load and use someone else’s pretrained ResNet model to make probabilistic predictions on 1000 classes.
Summary:Welcome to the world of deep learning¶
This set of tutorials is over, and our learning journey has finally come to an end. By now, you should have mastered the basic concepts of machine learning, deep learning, and be able to use MegEngine to write neural network code for simple scenarios, as well as read other people’s work coded with MegEngine. It may still take some time to become familiar with these concepts, but… Welcome to the world of deep learning!
Here are some directions for you to explore next (depending on whether you are research-oriented, engineering-oriented, or well-rounded):
Select branch areas for research, and use MegEngine to reproduce classic experiments
All the code in this set of tutorials revolves around the image classification task in the field of computer vision, you can try to reproduce ResNet yourself. Now is the time to touch more types of computer vision tasks, such as object detection, instance style, super Resolution, etc.; you can also try other traditional domain problems solved with deep learning, such as natural language processing, recommender systems, and so on. In addition to reproducing other people’s code, you can also try to participate in some competitions, you will have some inspiration if you do more.
In order to try some cutting-edge ideas, you may actively expand the existing functions of MegEngine; in order to save model training time, you may have a better understanding of MegEngine’s distributed training; In the case of limited computing resources, In order to save video memory, you may learn about MegEngine’s heavy computing technology.
Understanding MLOps in Engineering Practice
Everything we’ve learned so far can only be considered the foundation of MegEngine model development. Reliably and efficiently deploying and maintaining machine learning models in production requires an understanding of the entire MLOps process. Taking the reasoning process of the above ResNet pre-training model as an example, we use the Python (+GPU) environment used for training, but our purpose is to hope that the model can be deployed to other platforms and devices to perform extremely efficient inference under limited conditions. See Model Deployment Overview and Process Recommendations for more details.
In order to serve the business scenario requirements, we will touch more inference-related functions of MegEngine.
From zero basic state to new MegEngine, this is an unforgettable journey, we learned how to do basic things right, and take the initiative to think. It will take a long time to keep trying to get things right and become an experienced MegEnginer.
Expansion material¶
模块化你的项目
In the tutorial, our code is basically organized as a single file for presentation purposes. But in actual programming practice, in order to improve efficiency, we should learn to organize our project code in a modular form. The code in MegEngine/Models is a good example, and BaseCls is also an excellent reference. I also hope that you can contribute more excellent MegEngine projects to the community~
Try to modularize the code in the tutorial in the form of data, model, train, test.
重视 Benchmark 产生的影响
As a classic benchmark dataset in the field of computer vision, ImageNet has far-reaching significance for promoting the development of the field. But at the end of the research, it is easy to evolve into a relatively high point on the validation set through continuous experiments and parameter tuning. In a sense, this is also an overfitting phenomenon, except that the object becomes the validation set data.
In addition, practice has shown that many models that perform well on ImageNet are not as expected for actual production tasks. This has a lot to do with the differences between the distributions of the datasets, for example a model trained with oil paintings may not perform well on sketch data. Therefore, for a specific deep learning industrial scenario, it is necessary to figure out what the input data usually looks like in the actual production environment. In this way, when the standard is used for training and verification data, the distribution of the data can be made as similar as possible, and an accurate benchmark can be established. In many cases, there is no problem with the model structure itself, but it may be that the benchmark setting is not scientific enough.
references¶
- 1
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: a large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, 248–255. Ieee, 2009.