使用 FastAPI 快速部署 MegEngine 模型¶
本教程涉及的内容
快速回顾 MegEngine 模型开发的基本流程,了解如何加载训练好的模型;
学习 FastAPI 的基本使用,理解服务端和客户端等相关概念;
将训练好的 MNIST 模型在本地进行服务部署,并进行推理验证。
See also
本教程所用到的源码: examples/deploy/fastapi (可与 Getting started with MegEngine 代码对比)
需要阅读 FastAPI 官网文档并在你的环境中安装好该框架。
这不是 MegEngine 模型推理的最佳实践!
本篇教程的内容仅仅是为了帮助概念入门,实际生产环境中通常不会用到这样的部署模式。
快速回顾:模型开发步骤¶
查看 MNIST 数据集介绍
MNIST 1 手写数字数据集中包含 60,000 张训练图像和 10,000 张测试图像,每张图片是 28x28 像素的灰度图。 如今 MNIST 已然成为机器学习领域的 “Hello, world!”, 用来验证框架和库的可用性。

By Josef Steppan - Own work , CC BY-SA 4.0¶
你可以选择 Clone 文档获得源码,或者手动进行下载:
git clone git@github.com:MegEngine/Documentation.git --depth=1
cd Documentation
接下来的步骤在快速上手以及入门教程中都有介绍过(不关注这些步骤的读者只需运行代码即可):
训练 MNIST 手写数字分类模型(推荐使用 GPU 环境,
--help查看帮助信息):python3 examples/deploy/fastapi/train.py --data /path/to/MNIST
默认总共训练 30 epochs, 每 10 epochs 保存一次检查点,训练同时记录日志信息。
你应当可以看到模型精度在 99% 以上,并且在
fastapi/output目录下有文件生成。在 MNIST 测试集上进行测试,通过
--model指定权重路径:python3 examples/deploy/fastapi/test.py --data /path/to/MNIST \ --model examples/deploy/fastapi/output/checkpoint.pkl
使用单张图片进行推理预测,通过
--image指定图片路径:python3 examples/deploy/fastapi/inference.py --image /path/to/image \ --model examples/deploy/fastapi/output/checkpoint.pkl
如果未给定图片路径,则会默认使用这张图片:
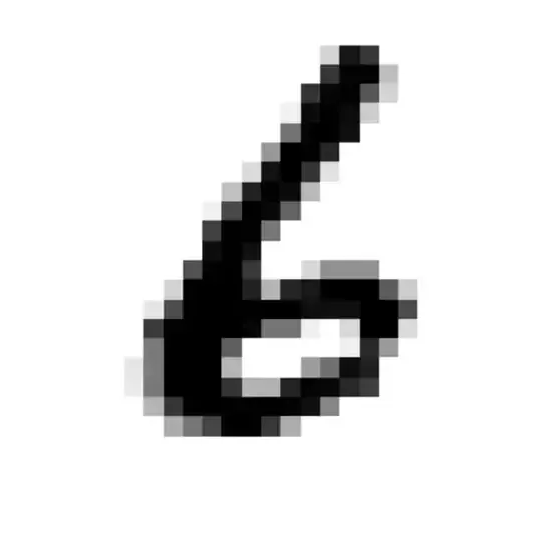
你将会看到输出预测这张图片的分类为数字 6.
Note
到这一步,我们可以说是开发出了一个能够识别 “白底黑字手写数字” 的模型。 上面的单张图片的推理过程,即给定输入图片 \(\mathcal{I}\), 输出对分类的预测—— 这可以作为服务部署到服务器设备上。
使用 FastAPI 部署模型¶
本小节我们将讨论部署(Deploying)的有关概念,主要侧重为服务器(Server)端部署, 通过将模型部署到一台服务器上,客户端(Client)则将能够向服务器发送请求(Request)来完成交互。 我们不会讨论过多有关 Client-Server 交互的概念,你可以在互联网上找到相当多介绍它们的材料。
机器学习模型存在于 等待接收来自客户端提交的预测请求的 服务器中,推理逻辑与 inference.py 基本一致:
import megengine as mge
from model import LeNet
checkpoint_path = "output/checkpoint.pkl"
checkpoint = mge.load(checkpoint_path)
if "state_dict" in checkpoint:
state_dict = checkpoint["state_dict"]
model = LeNet()
model.load_state_dict(state_dict)
# Input data (request from the client)
# ...
pred = model(data)
# Return the result back to the client
当模型被部署到服务器上时,输入的数据 data 将来自于从客户端发往服务器的请求, 换而言之,想要让服务器进行正确的预测,客户端的请求中必须包含正确的输入信息; 最终服务器需要将预测并且处理好的结果返回给客户端,以供客户端用作其他用途。我们将通过 FastAPI 来快速地搭建起服务器应用的原型。
FastAPI 实例的创建¶
创建 FastAPI 实例的步骤很简单:
>>> app = FastAPI()
接着我们需要创建用于推理服务的端点(Endpoints),一切准备就绪后,只需要运行:
>>> uvicorn.run(app)
这样你能够快速地搭建起一个异步网关接口(ASGI)实现,其中 FastAPI 负责提供 API,
uvicorn 负责提供网关服务,只是目前它还不能够做任何事情。
我们不需要理解背后的技术细节,就能够完成教程后面的步骤。
接下来我们要做的事情是:1. 完成请求与返回逻辑; 2. 将模型推理的步骤加入相应流程。
Endpoints 的创建¶
在 FastAPI 中创建为实例 app 创建端点的方法很简单:
@app.get("/")
def home():
return "The server is woking~ Now head over to http://localhost:8000/docs"
当运行 uvicorn.run(app, host="127.0.0.1", port=8000) 时,
将会在监听发送到本地 8000 端口 / 路径的所有 get 请求,
并按照 home() 中的逻辑处理和返回信息,上面的例子中将返回文本信息。
你完全可以为不同的机器学习模型创建多个端点(假定域名为 mymodel.com ):
mymodel.com/handwrittern-digit-classification
mymodel.com/object-detection
mymodel.com/speech-to-context
这样你就能够为能够访问到你服务器的多个客户端提供服务。
本教程中将假设服务器为你本地的机器,你将通过创建一个异步的 prediction
函数来定义端点 /predict, 并负责处理该端点的所有逻辑:
@app.post("/predict")
async def prediction(file: UploadFile = File(...)):
# Get data <-------- clients
# Do something here...
mdoel(processed_data)
# Do something here...
# Return ----------> clients
所以我们要做的事情是,发送一张带有手写数字图片数据的请求,希望返回预测分类。
HTTP 请求的类型
客户端和服务器之间通过一种称为 HTTP 的协议相互通信。两个非常常见的行为是:
GET-> 从服务器检索信息。POST-> 向服务器提供信息,用于响应。
与存放在服务器端点上机器学习模型的交互通常通过 POST 完成,
因为需要客户端需要向其提供一些信息以用于预测。
在上面的 prediction 代码中,需要提供 file, 也即将文件作为请求中的参数。
完整的 Server 实现¶
请参考 examples/deploy/fastapi/server.py 中给出的代码,其中 prediction 实现如下:
@app.post("/predict")
async def prediction(file: UploadFile = File(...)):
filename = file.filename
fileExtension = filename.split(".")[-1] in ("jpg", "jpeg", "png")
if not fileExtension:
raise HTTPException(
status_code=415, detail="Unsupported file provided.")
if file.content_type.startswith('image/') is False:
raise HTTPException(
status_code=400, detail="File is not an image."
)
contents = await file.read()
image_stream = io.BytesIO(contents)
image_stream.seek(0)
file_bytes = np.asarray(bytearray(image_stream.read()))
image = cv2.imdecode(file_bytes, cv2.IMREAD_COLOR)
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image = cv2.resize(image, (32, 32))
image = np.array(255 - image)
image = mge.Tensor(image).reshape((1, 1, 32, 32))
logit = model(image)
label = F.argmax(logit).item()
return {
"filename": file.filename,
"contenttype": file.content_type,
"likely_class": label,
}
参考实现的逻辑非常简单,对文件的拓展名和类型进行了检查,看是否是图片;
接着以字节流的形式读入图片,转换成 ndarray 格式后借助 OpenCV 进行读入;
后面的处理步骤就是我们比较熟悉的推理过程了;最终我们返回了一个字典,
其中 likely_class 即模型预测的分类结果。
See also
这不是唯一的实现方式,你可以查阅 FastAPI 等文档进行自己的实现。
运行 server 脚本,访问 http://localhost:8000/ 即可看到服务器已经成功启动!
python3 examples/deploy/fastapi/server.py
使用 FastAPI 客户端快速验证¶
FastAPI 框架的另一个便捷之处在于,你可以通过访问 http://localhost:8000/docs 来启动一个内置的客户端,以便模拟发送请求,用于快速进行功能和结果的验证。
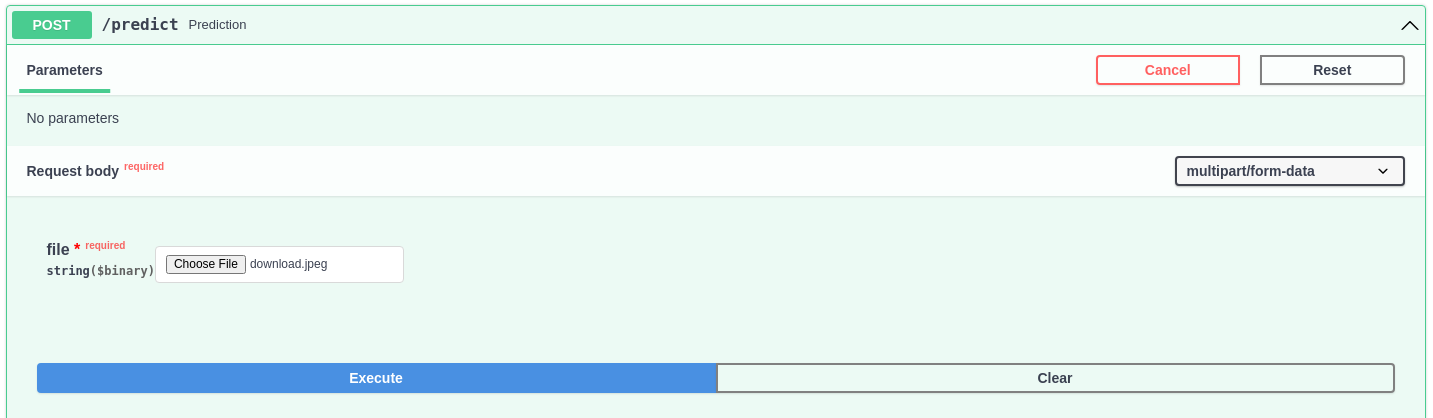
点击
/predict端点,将其中的内容展开;点击
Try it out按钮,在file一栏选择一张白底黑字的手写数字图片文件上传;点击
Execute发送POST请求,服务器将会给你返回对应的预测信息。
这种方式有什么问题?¶
前面提到,这种方式可以方便快捷地作为 Demo 进行验证和演示,但不是生产环境下的最佳实践。
最主要的两点原因为: 1. 可移植性差;2. 性能不够好。
推理部署强调可移植性
我们希望训练好的模型能够在不同的平台和设备上运行,比如手机、汽车等等。 目前的这种推理方式依赖原生 Python 运行时,且无法摆脱 GIL 带来的影响,在性能受限的场景下难以发挥作用。 因此我们会希望 MegEngine 模型能够被序列化保存并加载到没有 Python 依赖项的进程中。
推理部署强调极致性能优化
为了方便调试,MegEngine 默认使用动态图模式,在此模式下所有语句都是以解释的方式立即执行的; 实际上,MegEngine 支持切换到静态图模式,这种模式能够拿到更多的图信息, 在运行期间可以进行各种优化以提高性能。就好像编译执行的语言通常都会比解释执行的语言更快一样。
参考 Just-in-time compilation (JIT) 页面,你能看到更多有关动态图和静态图的解释。
在接下来的教程中,你会看到我们如何通过 MegEngine 的即时编译技术将动态图转换为静态图, 并且序列化导出,使之能够部署到对性能和资源占用要求都比较高的环境中去,我们将接触到 MegEngine Lite 来充分发挥 MegEngine 的多平台推理能力,同时兼顾高精度和高性能的要求。
拓展材料¶
参考文献¶
- 1
Yann LeCun, Corinna Cortes, and CJ Burges. Mnist handwritten digit database. ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist, 2010.