使用 Load and run 自动获取最优推理加速配置参数#
使用 Load and run 进行模型推理测速时,MegEngine 提供了大量的配置选项用于探索针对特定模型的推理加速。 这些配置选项灵活繁多,对于模型开发者而言有一定的启发意义。但对于部署而言,繁多的选项意味着较大的用户使用负担。 为了减少部署时用户的使用负担,Load and run 实现了 fitting 模式用于自动的进行推理时最优配置选项的选择, 减少部署时用户使用负担,提高用户使用体验。
准备工作#
编译 Load and run#
如果只需要使用 Load and run 来获取给定平台上的最优配置,正常编译即可,编译过程参考 Load and run 获取与编译 如果需要将相应配置,模型以及相关缓存打包,由于需要用到megengine json相关的部分,编译时需要开启相关设置:
-DMGB_ENABLE_JSON=1
准备模型#
备注
fitting 模式在不打包模型的情况下,可以支持 MegEngine Lite, MegEngine 的模型
fitting 模式如果需要打包模型,目前支持 MegEngine 的模型,其他类型的模型由于接口原因,暂时不支持打包操作
使用fitting 获取模型最优的推理配置#
备注
fitting 默认的推理后端为XPU,在有CUDA的设备上默认使用GPU,其他设备上默认使用CPU.
基本流程
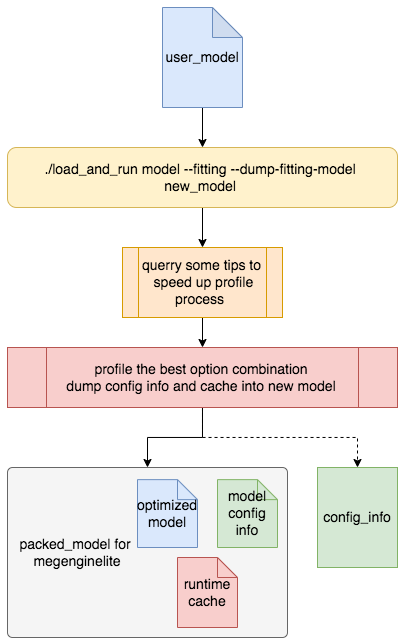
常见用法#
# 基本用法
./load_and_run <model_path> --fitting
#GPU可用设备上使用CPU
./load_and_run <model_path> --fitting --cpu
模型dump#
# 基本用法
./load_and_run <model_path> --fitting --dump-fitting-model <new_model_path>
#GPU可用设备上使用CPU
./load_and_run <model_path> --fitting --cpu --dump-fitting-model <new_model_path>