将动态图转为静态图(Trace)¶
注解
一般的模型训练中推荐用动态图,只有在有必要的情况下才编译静态图。( 直接跳转到用法 )
动态图和静态图¶
MegEngine 默认使用 动态计算图 ,其核心特点是计算图的构建和计算同时发生(Define by run)。
原理: 在计算图中定义一个
Tensor时,其值就已经被计算且确定了。优点: 这种模式在调试模型时较为方便,能够实时得到中间结果的值。
缺点: 但是由于所有节点都需要被保存,这就导致我们难以对整个计算图进行优化。
MegEngine 也支持 静态计算图 模式,将计算图的构建和实际计算分开(Define and run)。
原理: 在构建阶段,MegEngine 根据完整的计算流程对原始的计算图进行优化和调整, 得到更省内存和计算量更少的计算图,这个过程称之为 “编译” 。编译之后图的结构不再改变,也就是所谓的 “静态” 。 在计算阶段,MegEngine 根据输入数据执行编译好的计算图得到计算结果。
优点: 静态图相比起动态图,对全局的信息掌握更丰富,可做的优化也会更多。
缺点: 但中间过程对于用户来说是个黑盒,无法像动态图一样随时拿到中间计算结果。
通过浏览本小节末尾的 trace 进阶设置 部分,你可以了解到静态图的更多使用情景。
静态图编译优化举例¶
下面我们举例说明静态图编译过程中可能进行的内存和计算优化:
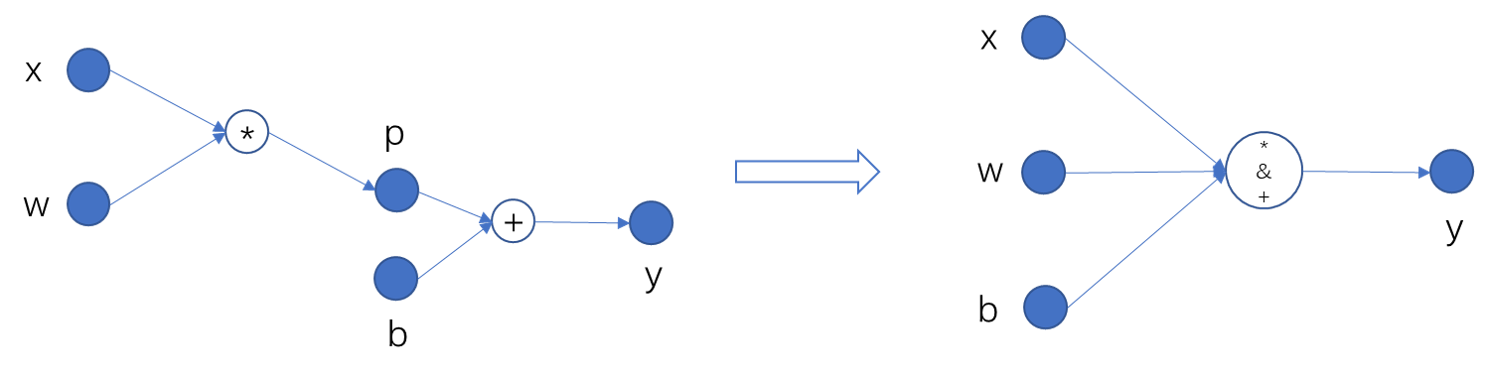
在上图左侧的计算图中,为了存储 x, w, p, b, y 五个变量,
动态图需要 40 个字节(假设每个变量占用 8 字节的内存)。
在静态图中,由于我们只需要知道结果 y, 可以让 y 复用中间变量 p 的内存,
实现 “原地”(Inplace)修改。这样,静态图所占用的内存就减少为 32 个字节。
使用 trace 装饰器¶
MegEngine 提供了很方便的动静态图转换的方法,几乎无需代码改动即可实现转换。
假设我们写好了一份动态图代码,其中训练部分代码如下:
for epoch in range(total_epochs):
total_loss = 0
for step, (batch_data, batch_label) in enumerate(dataloader):
data = mge.tensor(batch_data)
label = mge.tensor(batch_label)
# 以下代码为网络的计算和优化,后续转静态图时将进行处理
with gm:
logits = model(data)
loss = F.loss.cross_entropy(logits, label)
gm.backward(loss)
optimizer.step().clear_grad()
total_loss += loss.numpy().item()
print("epoch: {}, loss {}".format(epoch, total_loss/len(dataloader)))
我们可以通过以下三步将上面的动态图转换为静态图:
将循环内的网络计算和优化代码提取成一个单独的训练函数,如下面例子中的
train_func();将网络所需输入作为训练函数的参数,并返回任意你需要的结果(如计算图的结果和损失函数值);
修改后的代码如下:
from megengine.jit import trace
@trace
def train_func(data, label, *, opt, gm, net): # *号前为位置参数,*号后为关键字参数
with gm:
logits = model(data)
loss = F.loss.cross_entropy(logits, label)
gm.backward(loss)
opt.step().clear_grad()
return loss
for epoch in range(total_epochs):
total_loss = 0
for step, (batch_data, batch_label) in enumerate(dataloader):
data = mge.tensor(batch_data)
label = mge.tensor(batch_label)
# 调用被 trace 装饰后的函数
loss = train_func(data, label, opt=optimizer, gm=gm, net=model)
total_loss += loss.numpy().item()
print("epoch: {}, loss {}".format(epoch, total_loss/len(dataloader)))
对于上述代码,我们作进一步的解释:
jit: 即时编译 (Just-in-time compilation)的缩写,这里作为整个静态图相关模块的名字。trace:得到静态图的一种方式,直译为 “追溯”, 含义为通过追溯输出(比如损失值、预测值)所依赖的网络结构,得到整体的计算图,再进行编译。参数列表 :
trace在编译静态图时会根据传入参数是位置参数还是关键字参数来采取不同的处理方式。 其中位置参数用于传入网络的输入如数据和标签,关键字参数用于传入其它变量,如网络和优化器等。
trace 进阶设置¶
指定静态图构造方式¶
MegEngine 在编译静态图时有 “动态构造” 和 “静态构造” 两种模式(默认使用前者)。
在绝大部分情况下,两种模式下构造出的静态图并没有区别,使用中也没有分别。
我们可以指定 symbolic 参数来指定构造方式,示例代码如下:
from megengine.jit import trace
@trace(symbolic=True)
def train_func(data, label, *, opt, gm, net):
pass
设置为 True 表示 “静态构造” 或者 “根据符号构造” ——
原理: 此时,计算图中的所有数据节点(即张量)被视为符号(即
symbolic)。 它们仅仅作为占位符(Placeholder),不产生实际的内存分配,也没有实际的值。 此时计算图的编译过程完全取决于计算图的结构,而不取决于张量的具体值,是真正的 “静态”。优点: 始终高效,能充分利用静态图的内存优化。
缺点: 如果网络中包含了需要运行时动态信息才能计算的条件语句,将会失败。
设置为 False 表示 “动态构造” 或者 “根据值构造” ——
原理: 被装饰的函数在第一次被调用时会根据输入的数据执行一次计算构建出一个动态图。 接着将这个动态图会被编译静态图。此后该函数的所有调用都会运行这个静态图,而不再依赖调用时输入的值。 此种模式可以视为 “动态构建第一次,此后静态运行”。
优点: 根据第一次运行时信息的不同,可以构建出不同的静态图。
缺点: 由于第一次的运行在动态图模式下,无法利用静态图的内存优化,通常会耗费更大的内存。 这可能导致本来在静态图模式下可以运行的网络,在第一次运行时由于内存不够而失败。
警告
在动态构造模式(设置为 False)下,如果条件语句出现在循环语句内,在循环的第一次执行中构造出的静态图将固定不再改变 (即使在循环的后续执行中,该条件语句的结果发生了变化)
将参数固定以便导出¶
有的时候我们希望将一些参数(比如卷积层的卷积核等)固化下来,因此需要指定 capture_as_const = True :
from megengine.jit import trace
@trace(capture_as_const = True)
def train_func(data, label, *, opt, gm, net):
pass
注解
如果想要使用 dump 导出模型序列化文件并进行后续处理,
则必须在 trace 时固定参数。
减少访存操作实现加速¶
通常,模型中不仅含有计算受限的操作,还含有一些访存受限操作(如 Elemwsie ). MegEngine 内嵌了 Codegen 优化机制,它可以在运行时将模型中多个操作融合起来, 并生成可以在目标机器上运行的代码,以此减少访存操作从而达到加速的目的。
MegEngine 的 Codegen 目前集成了三种后端,分别是 NVRTC, HALIDE 和 MLIR. 其中 NVRTC 和 HALIDE 仅支持在 GPU 上使用,MLIR 则同时支持 GPU 和 CPU, 不同的后端生成代码的策略有所不同,所以运行效率也各异。
我们可以通过设置 MGB_JIT_BACKEND 环境变量来改变 Codegen 的后端,例如:
export MGB_JIT_BACKEND="NVRTC"
该环境变量在 NVIDIA GPU 环境下可取的值为 NVRTC, HALIDE 和 MLIR, 默认值为 HALIDE.
对于 CPU, 目前暂时仅支持 MLIR 后端。
警告
如果想要使用 MLIR 后端, 需要单独编译 MegEngine. 在使用 CMake 时换成如下命令:
cmake .. -DMGE_WITH_JIT=ON -DMGE_WITH_JIT_MLIR=ON -DMGE_WITH_HALIDE=OFF
然后设置如下的环境变量:
export MGB_JIT_BACKEND="MLIR"
指定代码不被转换¶
使用 exclude_from_trace ,其中的代码不会被 trace, 且允许访问静态区域的 Tensor .
示例代码如下:
from megengine import jit, tensor
@jit.trace
def f(x):
x += 1
with jit.exclude_from_trace(): # 不对下面的 if 语句进行 trace
if i % 2 == 0:
x += 1
return x
for i in range(3):
x = tensor([1])
print(f(x))
输出为:
Tensor([3], dtype=int32, device=xpux:0)
Tensor([2], dtype=int32, device=xpux:0)
Tensor([3], dtype=int32, device=xpux:0)