


博客
一、背景
在MegEngine imperative runtime的早期开发中,我们面临着一些的性能优化问题。除了一些已知需要重构的地方(早期设计时为了开发效率而牺牲性能的妥协),还存在一些未知的性能问题需要用profiler进行观测和分析才能发现。MegEngine的imperative runtime是一个由Python和C/C++编写的模块,对于这类程序,各种profiler多到令人眼花缭乱。在调研各种profiler的过程中,我们也踩了不少的坑,比如发现两个profiler对同一个程序的profiling结果差异巨大,我们起初怀疑其中一个profiler的准确性有问题,最后发现是两者的观测对象不同,其中一个只profiling程序的CPU time,而另一个profiling wall clock time。虽然一些这样的信息在文档的某些角落里能够找到,但很多使用者可能在踩了坑之后才会注意到。如果一开始能找到一篇介绍各种profiler的特点、优势、不足和使用场景的文章,我们可能会节省不少时间。
因此本文尝试对这些经验进行总结,希望能够给初次使用这些工具的读者一些参考。性能优化是一个十分广泛的话题,它涉及CPU、内存、磁盘、网络等方面,本文主要关注Python及C/C++ 拓展程序在CPU上的性能优化,文章主要围绕着下面三个问题展开:
- Python及C/C++ 拓展程序的常见的优化目标有哪些
- 常见工具的能力范围和局限是什么,给定一个优化目标我们应该如何选择工具
- 各种工具的使用方法和结果的可视化方法
除此之外,本文还会介绍一些性能优化中需要了解的基本概念,并在文章末尾以MegEngine开发过程中的一个性能优化的实际案例来展示一个优化的流程。
二、基本概念
本节介绍性能优化中的一些基础概念:
2.1 wall clock time, CPU time 和 off-CPU time
衡量程序性能最直接的标准就是程序的运行时间,但仅仅知道程序的运行时间很难指导我们如何把程序优化地更快,我们想要更进一步地了解这段时间之内到底发生了什么。
Linux系统上的time命令能够告诉我们一些粗糙的信息,我们在命令行里输出下面的命令来测量检查某个文件的CRC校验码的运行时间:
time cksum \<some_file\>
以我的电脑(MacBook Pro 2018)为例,得到了以下输出:
8.22s user 1.06s system 96% cpu 9.618 total
这段文字告诉了我们时间都花在了哪里:
- 总时间 9.618s
- user时间 8.22s
- system时间 1.06s
其中user和system的含义是user CPU time和system CPU time, 之所以会把CPU的执行时间分为两个部分,是因为程序在运行时除了执行程序本身代码和一些库的代码,还会调用操作系统提供的函数(即系统调用,程序运行系统调用时有更高的权限),因此程序运行时通常会处于两种状态: 用户态和内核态: 内核态指的是CPU在运行系统调用时的状态,而用户态就是CPU运行非系统调用(即用户自己的代码或一些库)时的状态。
因此上面提到的user CPU time指的是用户态所花费的时间,而system CPU time指的是内核态花费的时间。
我们发现user CPU time + system CPU time = 8.22s + 1.06s = 9.28s并不等于总时间9.618s,这是因为这条命令执行的时间内,程序并不是总是在CPU上执行,还有可能处于睡眠、等待等状态,比如等待文件从磁盘加载到内存等。这段时间既不算在user CPU time也不算在 system CPU time内。我们把程序在CPU上执行的时间(即user CPU time + system CPU time)称为CPU time (或on-CPU time), 程序处于睡眠等状态的时间称为off-CPU time (or blocked time),程序实际运行的时间称为wall clock time(字面意思是墙上时钟的时间,也就是真实世界中流逝的时间),对于一个给定的线程: wall clock time = CPU time + off-CPU time。
通常在计算密集型(CPU intensive)的任务中CPU time会占据较大的比重,而在I/O密集型(I/O intensive)任务中off-CPU time会占据较大的比重。搞清楚CPU time和off-CPU time的区别对性能优化十分重要,比如某个程序的性能瓶颈在off-CPU time上,而我们选择了一个只观测CPU time的工具,那么很难找到真正的性能瓶颈,反之亦然。
2.2 性能观测工具
我们知道了一个线程执行过程中的CPU time 和 off-CPU time,如果要对程序的性能进行优化,这些还远远不够,我们需要进一步知道CPU time的时间段内,CPU上到底发生了哪些事情、这些事情分别消耗了多少时间、在哪里导致了线程被block住了、分别block了多久等。我们需要性能观测工具来获得这些详细的信息。通常情况下我们也将称这种观测工具称为profiler。
不同的观测对象对应着不同的profiler,仅就CPU而言,profiler也数不胜数。
按照观测范围来分类,CPU上的profiler大致可以分为两大类: 进程级(per-process, 某些地方也叫做应用级)和系统级(system wide),其中:
- 进程级只观测一个进程或线程上发生的事情
- 系统级不局限在某一个进程上,观测对象为整个系统上运行的所有程序
需要注意的是,某些工具既能观测整个系统也支持观测单个进程,比如perf,因此这样的工具同时属于两个类别。
按照观测方法来分类,大致可以分为event based和sampling based两大类。其中:
- event based: 在一个指定的event集合上进行,比如进入或离开某个/某些特定的函数、分配内存、异常的抛出等事件。event based profiler在一些文章中也被称为tracing profiler或tracer
- sampling based: 以某一个指定的频率对运行的程序的某些信息进行采样,通常情况下采样的对象是程序的调用栈
即使确定了我们优化的对象属于上述的某一个类别,仍然有更细粒度的分类。在选择工具之前要搞清楚具体的优化对象是什么,单个profiler一般无法满足我们所有的需求,针对不同的优化对象 (比如Python线程、C/C++线程等) 我们需要使用不同的profiler。并且,对于同一个优化对象,如果我们关注的信息不同,也可能需要使用不同的profiler。
2.3 Python进程模型
本文主要关注Python(包括C/C拓展) 程序的优化,一个典型的Python和C/C拓展程序的进程如下图所示: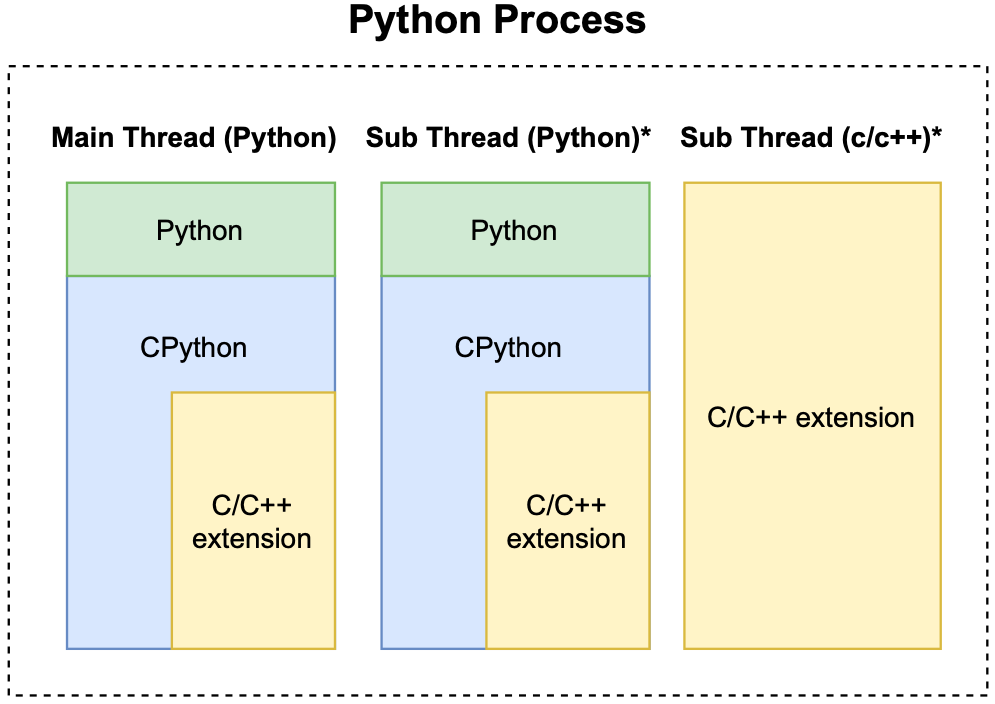
一个Python进程必须包含一个Python主线程,可能包含若干个Python子线程和若干个C/C++子线程。因此我们进一步把优化对象细分为三类:
- Python线程中的Python代码
- Python线程中的C/C++拓展代码
- C/C++线程
这里的Python线程具体指CPython解释器线程,而C/C线程指不包含Python调用栈的C/C线程。
三、profiler的分类和选择
我们从以下两个角度对profiler进行刻画:
- 是否支持profiling time、off-CPU time和wall clock time (CPU time + off-CPU time)
- 是否支持profiling C/C++ stack
- 是否能够从CPython解释器的调用栈中解析出Python调用栈
我们介绍将介绍6个profiler,分别为py-spy、cProfile、pyinstrument、perf、systemtap和eu-stack。为了方便大家进行选择,我们按照上面介绍的特征,把这些profiler分成了4类并总结在了下面的表格中 (其中✔、⚠、×分别表示支持、不完全支持和不支持):
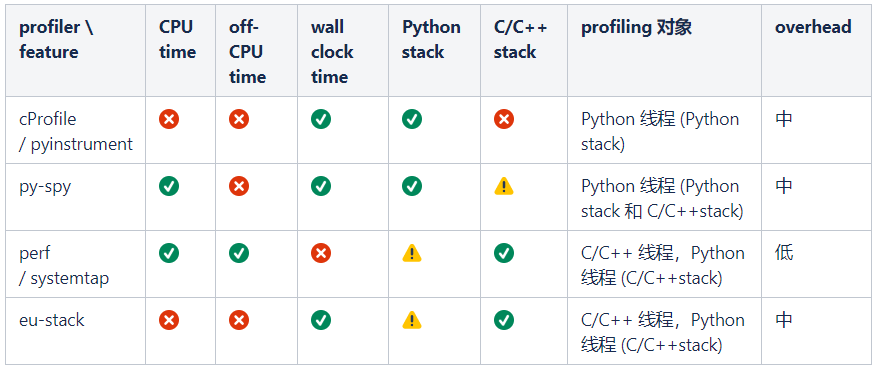
表格中第一种是纯Python profiler,只能观测Python线程中Python函数的调用栈,适合优化纯Python代码时使用,本文将介绍CProfile(Python的built-in profiler)和pyinstrument(第三方Python profiler),这类profiler还有很多,比如scalene、line-profiler、pprofile等,由于这些profiler在能力上差异不大,因此这里就不一一介绍了。
第二类是Python线程profiler,与第一类的主要区别是除了能够观测Python线程里的Python调用栈,还能观测c/c++拓展的调用栈,这一类只介绍py-spy。
第三类是系统级profiler,我们主要用来观测Python线程中的C/C拓展的调用栈和纯C/C线程,这类profiler虽然能够观测CPython解释器的调用栈,但由于不是专为Python设计的profiler,不会去解析Python函数的调用栈,因此不太适合观测Python stack。这一类工具我们将介绍perf和systemtap。
最后一类是对第三类的补充,由于第三类介绍的两个工具都无法在wall clock time (CPU time + off-CPU time) 上观测程序,eu-stack可以在wall clock time上采样程序的C/C++调用栈,因此可以作为这种场景下的profiler。
表格中的overhead指profiler运行时对被profiling程序的影响,overhead越大profiling的结果准确度越低。需要注意的是,任何profiler都无法做到绝对的准确,profiler本身对程序带来的影响、采样的随机性等都会对结果造成影响,我们不应该将profiling结果作为程序运行时的实际情况,而应该将其视为一种对实际情况的估计(这种估计甚至是有偏的)。
除了profiler,我们还需要一些工具来对profiling的结果进行可视化来分析性能瓶颈。与profiler不同的是,可视化工具一般具有较强通用性,一种广泛使用的工具是火焰图(flamegraph),本文将介绍flamegraph的使用方法,除此之外还会介绍一个火焰图的改进版工具: speedscope。
由于profiler的介绍里需要引用可视化工具,因此接下来我们先介绍可视化工具,再介绍profiler。
四、可视化工具
4.1 flamegraph
火焰图(flamegraph)是一个功能强大的可视化profiling结果的工具。它即可以对多种profiler的输出进行处理,也可以对处理后的结果进行可视化。它能够处理不同平台上的十多种profiler的原始输出,除了能够可视化cpu上的profiling结果,它也可以对一些内存profiler的输出结果进行可视化。
flamegraph的使用流程一般是对profiler的原始输出结果进行处理,之后再生成一个SVG文件,可以在浏览器里打开,效果如下:
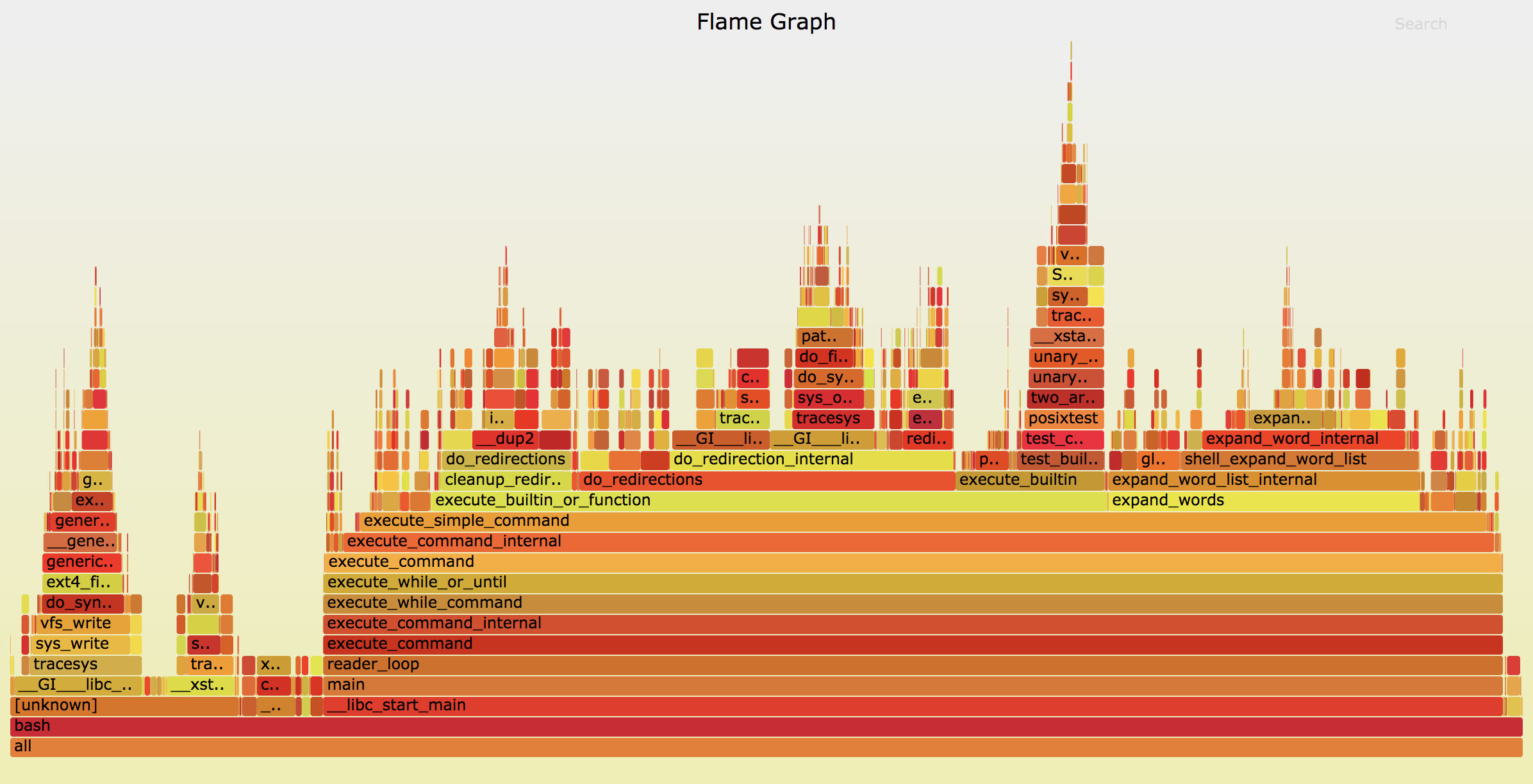
flamegraph的主要功能就是显示profiler采样的调用栈的频率分布,图中纵向堆起来的代表调用栈,调用栈中的矩形块的宽度代表该函数运行时被采到的频率(某个执行路径的时间占比与它被采样到的概率成正比,因此采样频率近似等于该执行路径的时间占比)。通过观察火焰图,我们可以看到程序都有哪些执行路径,以及每个执行路径的时间占比,然后对时间占比较大的性能瓶颈(或"热点")进行优化,来达到优化性能的目的。
如果想深入了解flamegraph,可以参考作者的主页或github repo:
- homepage: http://www.brendangregg.com/flamegraphs.html
- github repo: https://github.com/brendangregg/FlameGraph
4.2 speedscope
另外一个值得介绍的工具是speedscope。speedscope的使用方法和flamegraph类似,且兼容flamegraph的输出格式。与flamegraph相比,speedscope在两个方面具有优势: 1) speedscope在可视化效果、交互性等方面表现十分优秀,2) speedscope运行时的开销比SVG低很多,同时开很多窗口也不会造成明显卡顿。因此,我们推荐把speedscope与flamegraph结合在一起使用: 用flamegraph来处理不同工具的输出数据,用speedscope进行可视化。speedscope是一个web app,作者提供了一个可以直接使用的地址: https://www.speedscope.app/, 我们也可以在本地部署,但更前者更方便。本文主要以speedscope来可视化profiling结果,下面简单介绍一下它的使用方法:
进入https://www.speedscope.app/中,打开json格式的profiling结果 (我们会在下面各种profiler的使用方法中介绍如何将结果转为这种json)。可以看到以下界面 (与flamegraph的一个不同之处是speedscope的调用栈是倒过来的):
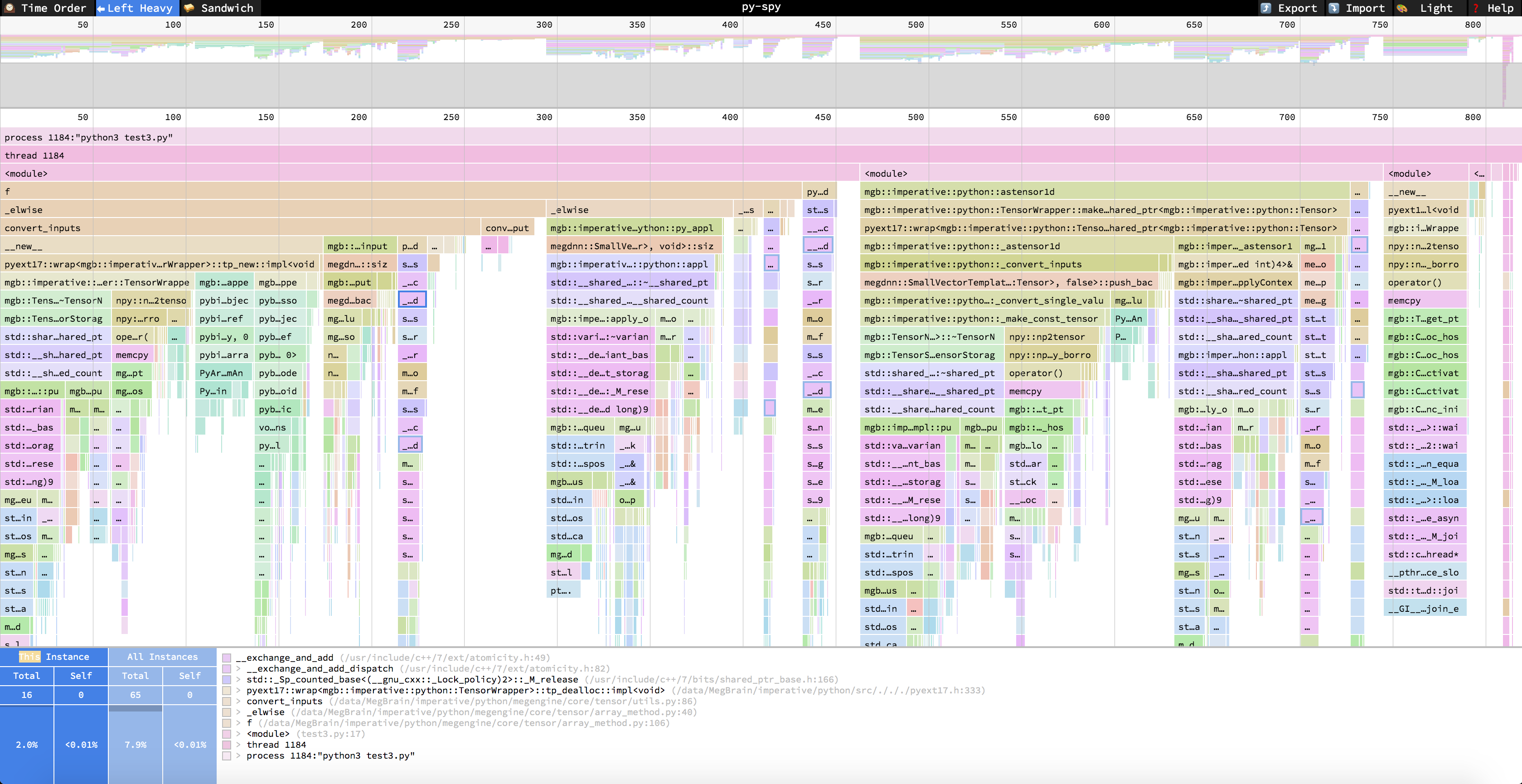
左上角可以选择三种模式:
- Time Order: 即时间轴模式,从左到右代表时间的方向,中间每一列代表改时刻采样的调用栈
- Left Heavy: 按照调用栈函数的时间占比(采样次数占比来估计时间占比)进行展示,即调用栈的每一层都按照左侧时间多右侧时间短的顺序来排序。点击任何一个调用栈中的函数:
- 可以在图中左下角看到该函数在当前调用栈(This Instance)的总开销(Total) 和自身开销(Self),以及该函数在所有出现过的调用栈(All Instances)中的总开销(Total)和自身开销(Self), 图中的整数代表被采样的次数,百分比为被采样的占比(近似等于时间占比)。
- 图下方的白色框内是该函数的调用栈。
- Sandwich:用函数的总开销和自身开销来排序,点击函数可以看到该函数的调用者和被调用者
更详细的介绍可以参考speedscope的官方repo: https://github.com/jlfwong/speedscope
tips:文章未完结,下篇请点击:python和c/c++拓展程序的性能优化(下)-博客-天元MegEngine
上一篇: 分享
JIT in MegEngine
下一篇: 分享
Python 和 C/C++ 拓展程序的性能优化(下)
 相关推荐
相关推荐Python 和 C/C++ 拓展程序的性能优化(下)
2021/04/07
MegEngine 使用小技巧:Profiler 使用手册
2023/08/30
借助 mperf 进行矩阵乘法极致优化
2023/03/27
MegEngine dataloader 新工具帮助定位性能瓶颈,快来体验吧!
2023/12/19
CPU 程序性能优化
2023/11/16

