


博客
点击此处查看上一篇文章:(中) 利用 MegEngine 分布式通信算子实现复杂的并行训练
五、层间模型并行
我们进入层间模型并行,刚才的层内模型并行我们介绍了相关原理和应用(全连接和组卷积)。层间模型并行和层内模型并行很不一样,主要就是简单模型并行和流水线并行。层间模型并行简单来说就是把网络的前半部分、中间部分和后半部分分开(甚至分成更多份),就像一条鱼,鱼头、鱼中和鱼尾。
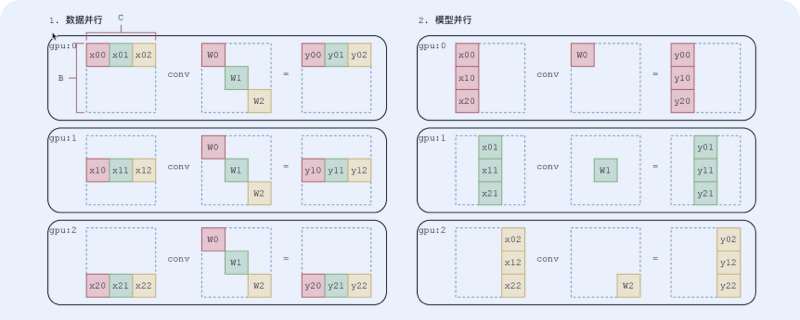
我们简单来看一下数据并行和层间模型并行的对比示意图。
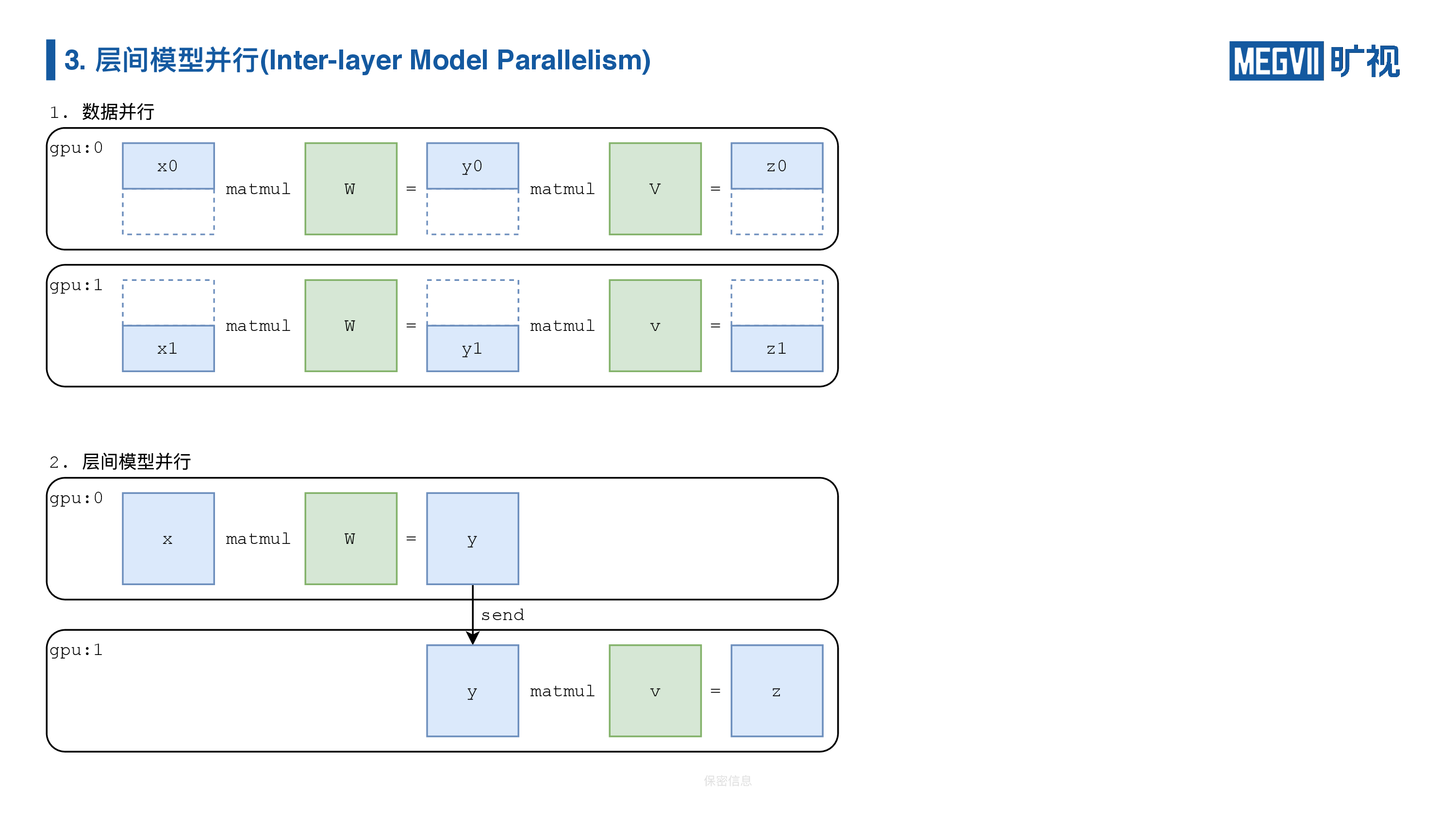
数据并行就是把数据切开,层间模型并行不切数据,而是把模型的前半部分和后半部分给拆分到不同的 GPU 上,这边就涉及到一个问题,怎么把“Y”第一块 GPU 的输出结果,给“放”到第二块 GPU 上,这里面就需要 send 操作。MegEngine 提供了八个集合通信算子,加上两个点对点通信算子——一个就是 send,一个就是 receive。这两个算子组成了层间模型并行的核心操作,接下来主要讲 send receive。
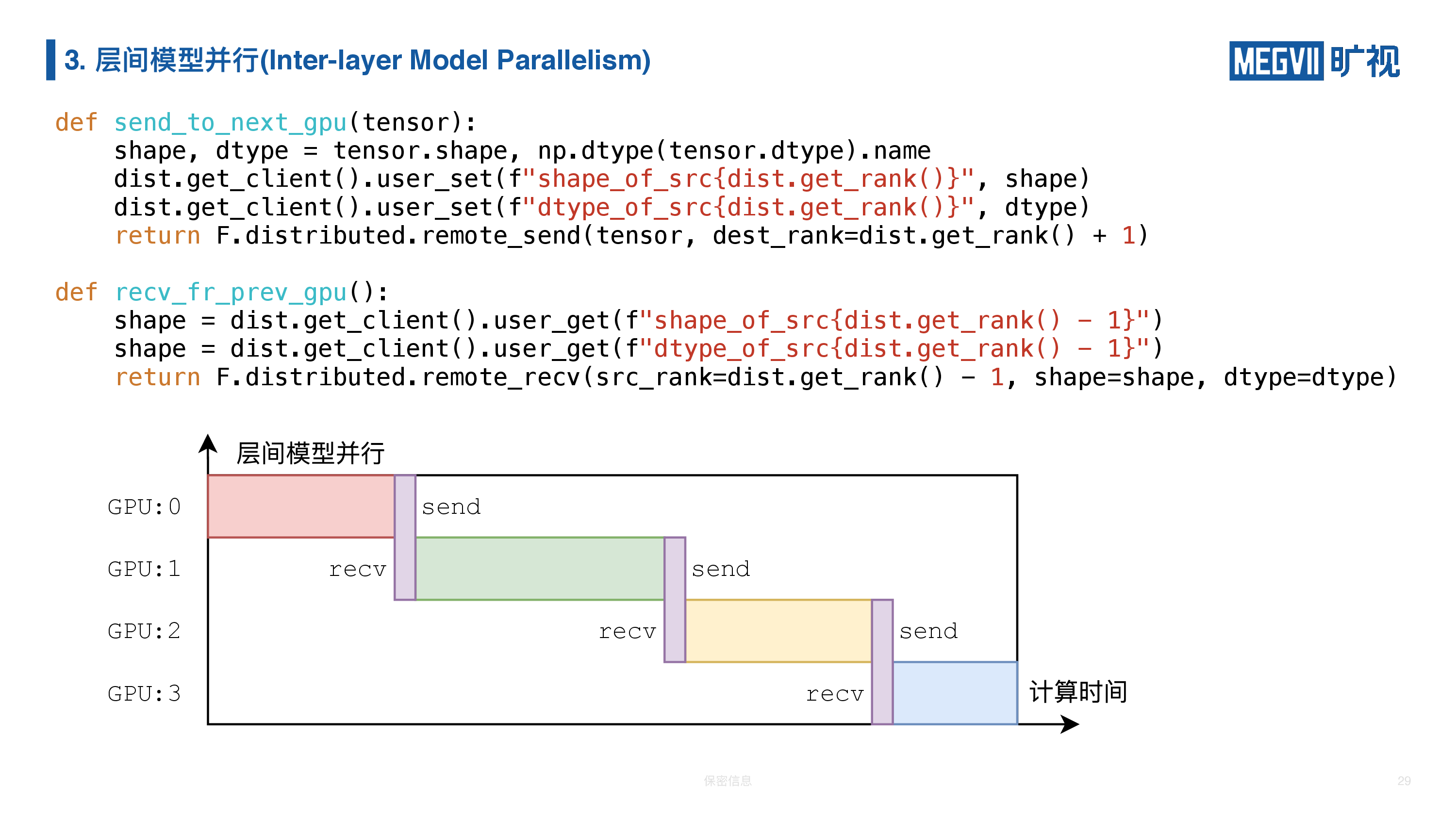
如果层间模型并行,我们用一个图表来抽象的话(如上图下半部分),横轴是计算时间,随着计算推进,纵轴是我们的计算设备(GPU),我们发现任务之间存在依赖关系,所以 GPU 0 算完后必须做 send 操作,同时卡 1 做 receive 接收卡 0 的结果,然后进行自己的计算,算完再 send,卡 2 receive……这样才能做完一个流程。
为了方便起见,我们这边又做了一次封装,第一个函数是把我们出来的计算结果给发到下一个 GPU,这个函数是下一块 CPU 调用的,就是它从上一个 GPU 去给它拿出去,MegEngine 自带的 recv 不带自动的形状和类型推导(讲师注:在 MegEngine 的下个版本即将支持),因此封装的时候我也简单实现了一下。
简单模型并行

我们直接看代码,在普通的数据并行里面,这是一个简单的 ResNet 18的模型,它总共有 17 层卷积加上一层全连接,在简单模型并行里面,如果它是第 1 块 GPU,它就负责第一部分的 5 层卷积,第2第 3 块各负责 4 层卷积,最后一块 GPU 负责 4 层卷积和最后的一层全链接。
在前传的时候先进行判断——当我们如果不是第 1 块 GPU 的话,我们就从前面一块卡拿数据。之后进行自己负责的卷积计算。得到结果后再次进行判断——如果不是最后一块 GPU,我们要把我的数据给送到下一块 GPU 上,如果是最后一块,就直接 return。
我们可以用代码来展示简单模型并行的推理和训练的结果:

在推理过程中,输入一张组(32张) 224分 辨率的图片,前三块 GPU 输出的都是网络的中间特征,最后的 GPU 输出的是网络的预测值。在训练当中值得一提的:第一,因为是模型并行,所以我们不需要进行 AllReduce;第二,前三块 GPU 在调用 gm.backward 时传入了一个 None,其实我们在设计 API 的时候,backward 任何东西都可以,backward None 在这里会发生什么?由于前传有一个 send,所以自动微分的时候就会插入一个 recv,它会先等待来自下游的梯度,然后进行正常的反传。
流水线并行
我们接下来讲流水线并行。简单的模型并行需要算完同一批次的全部的数据再给下一个批次的数据,实际上每一张卡都会有很长时间的空闲期,它要么在等上一块卡跑完,要么完成了自己这一批的任务,在等待下一批次的数据。
如果我们把一个批次的数据给分成很多小份的话,我们可以让第 0 块卡先算一小份,算完以后立马送给下一块卡,然后再计算下一小份,这样子的话这个时刻卡 0 和卡 1 可以同时算,空置率就下去了。

这就是流水线并行的一个核心思想,我们看一下它代码怎么实现。
比如在这个里面,我们想要把一份数据给拆成 4 份,我们用 F.split 将它拆成 4 分,然后遍历一遍这 4 份数据,如果它是第一块卡,它就拿那个数据,不然的话它会等,等着接收前一块卡的计算结果。不管怎么样拿到数据以后的事情就是进行计算,计算完以后我们要处理计算结果——和简单模型并行一样,如果他不是最后一块 GPU,我要把它送到下一块,如果它是最后一块 GPU 的话,就直接出来返回结果。
这就是流水线并行。当然到实际场景中流水线并行的代码需要考虑执行效率,没有这么简单,比如说会引入异步 send/recv,以降低等待时间。
我们不光要推理,我们还要训练,训练的话就涉及到一个反传,在普通的模型并行当中,我们的反传和前传时间轴是如下图所示:
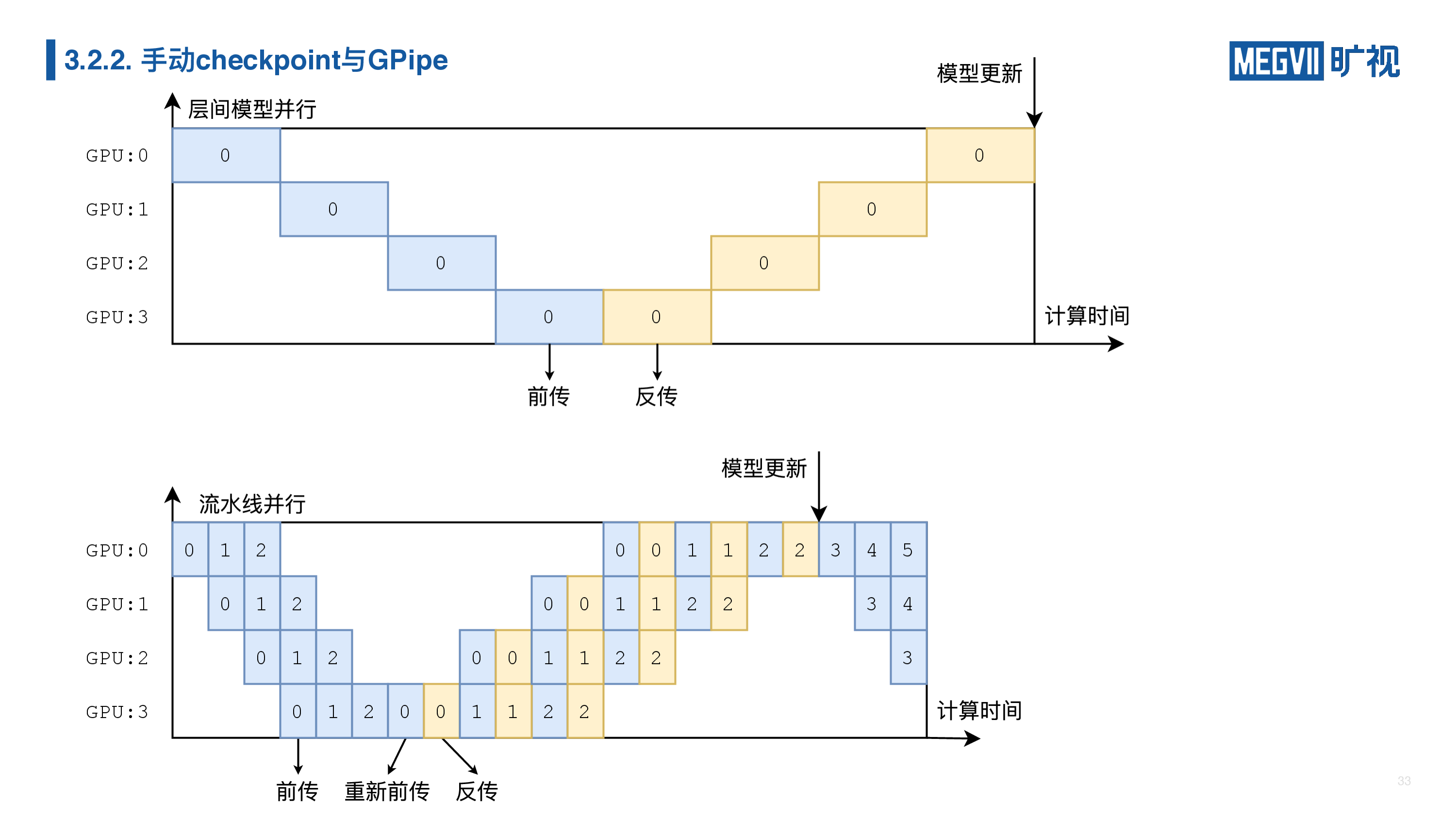
我们先前传完,再依次反传。但是在我们流水线并行里面,其实反传也是一个流水线的过程。但是这里面有个特殊的地方,注意一下重新前传(或重算)。如果我们不重新前传的话,意味着我们前面的这些中间结果都要保留着等待反传结束后才能丢弃/释放,这意味着我的宝贵的显存又要被浪费了,这样子的话我们还不如算完就全部扔掉,因为我已经把结果交给下一块 GPU 了,暂时就不需要了。而反传时我们还需要中间结果的时候,我大不了再重算一次(换句话说每张卡只要保留自己的输入就可以了)。重算后我们可以正常做反传,得到关于输入的梯度,然后把这份梯度传给上一张卡。上一张卡同样执行重算、反传和发送梯度,直到所有卡都完成了梯度计算。
重新前传的操作叫做 checkpoint 或 sublinear,在 PyTorch 里面有 checkpoint,在 MegEngine 里也有 sublinear,我们目前实现的是非常粗粒度的 sublinear,它不是中间保留几个结果重算部分就可以了,它其实是全部都重算了,这就是 GPipe。

前传还是一样的代码,如上图左侧给大家做一个参考。
反传是精妙的地方,我们拿到 label,loss 以后看一下,第一就是我们 GradManager,这是 MegEngine 一个非常重要的特性,就是 GradManager 可以对中间的 feature(就是中间结果)进行求导,所以我们可以在计算过程中对中间变量进行 attach,在 GPipe 的场景下,我们需要的是对输入的导数,所以我们在一开始就 attach 输入数据 x,然后进行前传(或者称为重算)。如果它是最后一张卡的话,我们就计算相应的损失,并把梯度算出来。通过 grad_to_prev_gpu,我们把关于输入的梯度传给了上一张 GPU。后一块卡关于输入的梯度即前一块卡输出的梯度 dy。我们通过 gm.backward(dy=grad)手动指定梯度,从而完成中间 GPU 的求导过程。这就是一个简单的 GPipe。
如果大家想试着玩一下这个 GPipe 的话,在 GitHub 上面 MegEngine Parallel Tutorial 是我写的,大家可以去跑一下玩一下。
上一篇: 分享
Python 和 C/C++ 拓展程序的性能优化(下)
下一篇: 分享
利用 MegEngine 分布式通信算子实现复杂的并行训练(中)
 相关推荐
相关推荐利用 MegEngine 分布式通信算子实现复杂的并行训练(中)
2021/04/26
利用 MegEngine 分布式通信算子实现复杂的并行训练(上)
2021/04/26
MegEngine 11-12 双月报:新版本发布,开发者福利课程,MegEngine 使用技巧,精彩不容错过!
2024/01/05
MegEngine 版本最新发布!新增支持寒武纪思元系列 AI 芯片训练和推理
2024/01/02
MegEngine dataloader 新工具帮助定位性能瓶颈,快来体验吧!
2023/12/19

